
Information security professionals may be quite familiar with security monitoring and commonly refer to frameworks such as COBIT or those from the US National Institute of Standards and Technology (NIST) and the International Organization for Standardization (ISO) to customize the design and security strategy for their environments. COBIT users can leverage the basic strategy of plan and organize, acquire and implement, deliver and support, and monitor and evaluate.
In 2012, the best-selling book Antifragile reviewed the decision-making process in an ever-changing world of unscheduled or unforeseen luck, uncertainty, probability, human error and risk. This was an attempt to suggest techniques to understand and manage the unknown.1 The known-unknown and unknown-unknown were covered further in The Black Swan a few years earlier.2 If the author of these publications had collaborated with the security operations center (SOC) personnel from an IT company, then the following recommendations would be the result of their efforts.
The challenge today is that this field is ever-changing, and threats are becoming more sophisticated. What is a repeatable process to ensure that the enterprise is always ready to meet this challenge? What are the use or test cases that one can use to meet or improve the standard of security monitoring?
These days, when ransomware, malware and attacks on managed devices proliferate, the first line of defense rests with the SOC and incident response team (IRT) to identify, monitor and respond to these attacks. In fact, these are not always attacks, since they may be reconnaissance (recons). Taking a step back, senior management must ask the initial question about whether to outsource the SOC, i.e., SOC as a Service or Security as a Service (SECaaS). Specific business or technical questions to make this decision may be hard to identify, but the following four questions may be asked at the onset of creating, revising or enhancing the incident management (IM) process:3
- What is the enterprise trying to protect?
- What are the threats?
- How does the enterprise detect them?
- How does the enterprise respond to threats?
The intent of this article is to outline a process to define a standard operational report for use cases to identify, monitor and respond to incidents and identify several security monitoring best practices. These reports should be tool agnostic. This process is not rocket science; it sets up a methodology to follow while adapting to the ever-changing threat landscape. However, it is mentioned that as the security incident event management (SIEM) tool is used to capture network and device activity, there are millions of network events that must be correlated with its rules to identify false positives, positive events, benign events or other events. There are limitations of a SIEM that must be evaluated against other logging systems.
Based on collective experience dealing with various customers, investigative reports that need testing have been identified, researched for implementation and customized within the enterprise. An organization needs to review whether the SIEM should be replaced with other logging tools to apply threat intelligence and further pinpoint the security event. Once that is done, the incident response process can be activated.
Using one approach, a standard set of test cases for network security monitoring for the SIEM could involve the following:
- Authentication tracking and account compromise detection—This involves administrator (admin) and user tracking.
- Compromised and infected system tracking—This involves malware detection by using outbound firewall logs, network intrusion prevention system (NIPS) alerts and web proxy logs, and internal connectivity logs and network flows, etc.
- Validating intrusion detection system/intrusion prevention system (IDS/IPS) alerts by using vulnerability data and other context data about the assets collected in the SIEM—While some may consider this outdated, this use case is still relevant in its modern form of using SIEM for alerts.
- Monitoring for suspicious outbound connectivity such as malicious domains being contacted, User Datagram Protocol (UDP) traffic attacks and data transfers by using firewall logs, web proxy logs and network flows—This involves detecting exfiltration and other suspicious external connectivity.
- Tracking system changes and other administrative actions across internal systems and matching them to allowed policy—This involves detecting violations of various internal policies, etc. It even includes root access from an unknown IP in a foreign country at 3 a.m. that leads to system changes.
- Tracking of web application attacks and their consequences by using web server, web application firewall (WAF) and application server logs—This involves detecting attempts to compromise and abuse web applications by combining logs from different components.4, 5
These sets of test cases were selected based on their ease of analysis and pro forma rules established within the tools that need to be customized based on the threat landscape of the enterprise and guidance from senior management. Other categories of test cases to consider include:
- Baseline network behavior based on established profiles and identified network activity of internal users, remote users and customers. Baseline profiles are established based on use, including time of day or night, size of download, type of download, and locations accessed. Users exceeding these baseline profiles will trigger escalation and forensic review.
- Baseline operating services, such as resource and performance review, and central processing unit (CPU) utilization based on established profiles maintained by the usage of enterprise resources. This includes memory usage, duration of logins (in days) and number of processes. It becomes quite sophisticated since the concept of a baseline profile can be applied to the usage of printers, downloading data to desktops/laptops or even the use of mobile personal digital assistants (PDAs).
- Identification of suspect internal hosts or programs. Each computer inside a subnetwork can use malware or a suspicious program to forward malware to another program or insider (internal employee or customer).
Additional use cases that require further reevaluation on a periodic basis are shown in figure 1.
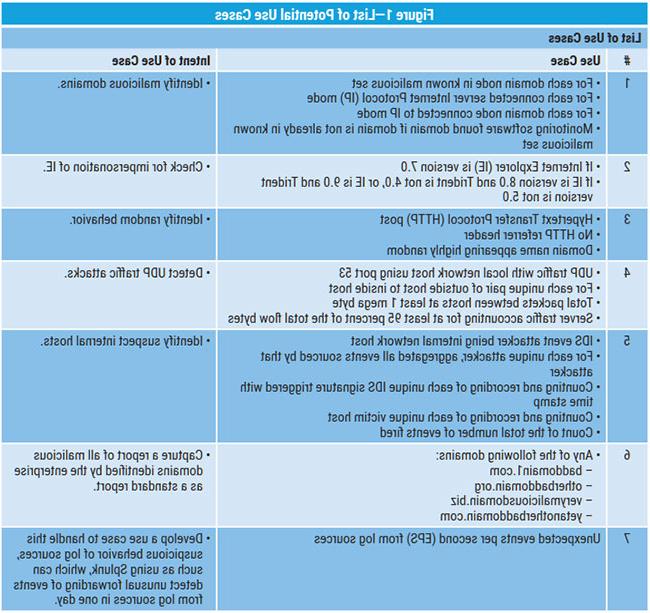
These use cases must be reevaluated periodically for their continued applicability. For enterprises attempting to grow their population of use cases, they can be amplified or supplemented based on threat intelligence received from their managed services security provider (MSSP).
The bottom line is that as part of their information security (InfoSec) playbook, organizations should rely on best practices for network security monitoring, which may include all or part of the following basic components:
- Baseline network behavior—Organizations need to establish a baseline network behavior over a period of time “to identify potential problems even before users start”6 experiencing them. “Once normal or baseline behavior of the various elements and services in the network are understood, the information can be used by the admin to set threshold values for alerts.”7 This includes internal and remote connections.8 For example, understanding the normal temperature and CPU utilization of the device will help the network administrator detect the deviation and take corrective actions before a malfunction occurs.
- Reports at every layer, where available—Management reporting based on each of the network layers and at multiple key points or nodes of failure should be established.
Networks function based on the open systems interconnection (OSI) layer and every communication in a network involves transfer of data from one system to another through various nodes, devices and links. Each element in the network that contributes to data transfer functions at one of the layers, such as cables at the physical layer, IP addresses at the network layer, transport protocols at the transport layer and so on. When a data connection fails, the failure can happen at any one of the layers or even at multiple points. Using a monitoring system that supports multiple technologies to monitor at all layers, as well as different types of devices in the network, would make problem detection and troubleshooting easier.9 - Determining the best strategy for the future—Today, organizations must decide whether to procure separate tools and integrate their use to solve separate network issues or use a centralized monitoring tool or third-party service that can provide such functionality. These decisions must be made based on the benefits, costs and other soft factors. Thus, “when an application delivery fails, the monitoring system can alert whether it is a server issue, a routing problem, a bandwidth problem or a hardware malfunction.”10
- Constant learning and adapting the organization’s defenses—Organizations should adapt their strategy by reviewing management reports, third-party intelligence and other industry activities, and the strategy should be supplemented by attending the meetings of organizations such as the Financial Services Information Sharing and Analysis Center (FS-ISAC). As an organization grows and its processes mature, IT infrastructure matures with the supporting strategy, too. As organizations merge or take on additional employees, this geometrically impacts the number of network security devices needed, network and wide area network (WAN) bandwidth, and storage space.
- Implementing high availability—Some may debate whether high availability (HA) is relevant to implementing security monitoring. However, its relevance can be seen both in monitoring and IM.
Most monitoring systems are set up in the network they monitor. This allows for quicker and better data collection from monitored devices. But if a problem occurs and the network goes down, the monitoring system can go down too, rendering all the collected monitoring data useless or inaccessible for analysis.11
Therefore, it is recommended to implement a monitoring strategy with HA through failover. HA ensures that the monitoring system does not have a single point of failure so even when the entire network goes down, the monitoring system is accessible, providing data to the network engineer for issue detection and resolution. One method for HA is failover, where the monitoring data collected by a network management system (NMS) are replicated and stored in a remote site. In case of failure at the primary monitoring system, the failover system can be brought up (or will automatically come up) and provide data needed for troubleshooting. To avoid a single point of failure, it is recommended to set up the failover system at a remote disaster recovery (DR) site.12 - Configuration management—It has been said that most network issues have their origin from incorrect configuration settings, however minor they may be. For example, Solarwinds has noted that when network changes are made (e.g., implementing new or revised configurations, adding firewall rules) the person responsible for making the changes may inadvertently block a business-critical application or allow nonbusiness traffic. “With the help of configuration management, when configurations are changed on devices—which include network and security devices, e.g., routers, switches or firewalls—the network administrator can verify that the changes being made do not break an already working feature.”13 Inadvertent errors can result in an extensive amount of time to either restore a prior configuration or remediate the new configuration. Also, configuration management needs to ensure that unauthorized or incorrectly defined configuration changes to devices are prevented or mitigated since they can lead to security lapses that include hacking and data theft. With a controlled, documented configuration management, administrators can ensure that appropriate changes are being made by appropriate people with the proper level of access.
- Adapting to virtualized environments—When using new technology, organizations cannot afford to have a myopic view of their security control posture. With a virtualized environment, some firms are adopting new technology such as a network monitoring.
A network monitoring switch integrates into the existing network security management infrastructure and provides information to the network management system via [simple network management] SNMP.14
- Knowing where the data reside—The bottom line is that security depends on what the enterprise is trying to protect. This includes the key corporate confidential and nonpublic material data that firms must protect to ensure their continued viability. Security tools, best practices and use cases all depend on the location, variability and skill set of individuals, along with a measurement of the risk and sensitivity of the data.
These best practices will help an enterprise to identify and remediate issues on an expeditious basis. With these use cases, one must decide how a template of use cases applies to one’s own organization. Each organization experiences attacks differently and reacts differently. The challenge is that there are so many use cases that can be collected in a contingency table for correlation; management has to review those that are most useful. But again, after management builds this contingency table of use cases, the firm must decide on three primary issues:
- What data require protection?
- Where are the data located?
- What is the data’s classification?
These questions are the driving force for these use cases and will drive the design of the network infrastructure.
Conclusion
 There are best practices and guiding principles that firms must rely on to develop, adjust and mature their security monitoring strategy, processes and procedures. From a base set, firms must adjust these based on a suite of use cases and defenses that must be documented, interrelated, managed for risk of their integration and growth, monitored, and reported. Looked at another way, the security professional can review a security device such as a SIEM or log management system and use the approach to determine by device the nature or objective of the use case that needs to be developed.
There are best practices and guiding principles that firms must rely on to develop, adjust and mature their security monitoring strategy, processes and procedures. From a base set, firms must adjust these based on a suite of use cases and defenses that must be documented, interrelated, managed for risk of their integration and growth, monitored, and reported. Looked at another way, the security professional can review a security device such as a SIEM or log management system and use the approach to determine by device the nature or objective of the use case that needs to be developed.
Figure 2 can be adjusted and sized based on the environment, extent of network activity and level of maturity of the monitoring process.
Endnotes
1 Taleb, N.; Antifragile: Things That Gain From Disorder, Random House, USA, 2014
2 Ibid.
3 Bollinger, J.; B. Enright; M. Valites; Crafting the InfoSec Playbook, O’Reilly Media Inc., USA, 2016
4 AlienVault, “SIEM Use Case Examples,” http://www.alienvault.com/solutions/siem-use-cases
5 InfoSec Institute, “Top 6 SIEM Use Cases,” 15 May 2014, http://resources.infosecinstitute.com/top-6-seim-use-cases/#gref
6 Solarwinds, Network Monitoring Best Practices, www.solarwinds.com/network-monitoring-best-practices
7 Ibid.
8 Ibid.
9 Ibid.
10 Ibid.
11 Ibid.
12 Ibid.
13 Ibid.
14 Ixia, Best Practices for Security Monitoring, June 2013, http://support.ixiacom.com/sites/default/files/resources/network-visibility-whitepapers/best_practices_for_security_monitoring.pdf
Larry Marks, CISA, CRISC, CISM, CGEIT, CFE, CISSP, CRVPM, CSTE, ITIL, PMP
Is a risk manager with extensive experience in managing and implementing processes, policies and technology regarding risk, security, governance, program management, compliance, internal controls and information security in the financial services, insurance, health care and telecommunications industries. He has helped manage project management offices at various Fortune 100 firms. Marks has been published in the ISACA Journal, (ISC)2 Journal, Project Management Journal and ProjectManagement.com.