
Patches are quick fixes of known software bugs that presumably were not known at the time that the software was released. Correcting such problems may be crucial for operations and can be a significant security concern—a known security vulnerability brings risk to the enterprise. Many high-profile cases of hackers exploiting unpatched systems to inflict massive damage are well documented.1, 2
By patching, administrators are not dealing with a zero-day exploit, i.e., a vulnerability that is exploited before the software creator/vendor is even aware of its existence, but with a known problem. Zero-day exploits lose their zero-day status when they are detected, which is typically quickly, and this is why they are normally used on the highest-value targets. Unlike zero-day exploits, long-unpatched systems have a lengthy time period during which they are vulnerable to attacks. When a software manufacturer releases a security advisory or patch, not only administrators and users, but also potential attackers know about the software issue. Therefore, one might assume that administrators would routinely eliminate any vulnerability by simply applying the relevant patch, which is available from the software manufacturer, but that assumption is not always correct.
Today’s heterogeneous, interconnected IT world and the complexity of software are strong obstacles to the assumed approach to applying patches. Software that is to be patched typically interfaces with or connects to other software. Assuming that the software manufacturer has properly tested a released software patch and that the patch has no side effects on the functionality that it is meant to patch, how do administrators know if systems that interface with or depend on the software that is to be patched are compatible with the patch? In theory, code, or software, should be “a bit like your home, where you’re allowed to be as messy as you like, as long as you keep your external interface to other citizens moderately civil,”3 i.e., software should be like a black box with defined interfaces, such as application programming interfaces (APIs) and specified inputs/outputs; no other software that uses it directly or indirectly should depend on anything but the interface specifications. However, in real life, things are more complex. Administrators cannot know for sure that other software that depends on the software that is to be patched will work with the patched version without testing, often exhaustively, because noncompatibility conditions may be triggered by rare events. For example, applying a (possibly critical) patch to the operating system can result in problems with the database that runs on top of the operating system. A recent high-profile example is the Spectre and Meltdown vulnerability, for which some application providers explicitly warned against patching.4
Therefore, to avoid exhaustive testing (which can prove the presence of issues, but not their absence), administrators must ensure compatibility with other software that uses the to-be-patched software by getting agreement from the other software vendors that their software is compatible with the patch—this is not easy, because the vendors need to analyze and test their software. Depending on the software vendor’s customer base, testing the patch may not be a high priority. Instead, the software vendor may decide to wait for their new release to provide software that is compatible with the patch. Meanwhile, patches cannot be applied to the original software with the problem. The highly touted heterogeneity of IT results in unpatched systems that administrators can and want to patch, but their operations teams request that they wait for interfacing/connecting system vendors to verify compatibility to avoid the risk of disrupting operations.
Industry articles and research verify the complexity of patch management. These statements describe the problem:
- “Often, these changes require rewriting, retesting, and redeploying the application, which can take months. I have recently talked with several large organizations that took over four months…”5
- “Over the years, we have seen a disturbing trend, where exploits enabled by vulnerabilities that have had patches for at least six months prior to the attacks have skyrocketed.”6
- “Forty percent of organizations polled admitted to applying less than 80 percent of patches successfully.”7
- A time frame of 18 months to patch is not unusual within enterprises.8
- Applications may continue to run on unpatched environments or language versions because they are incompatible with patched versions.9
Often, IT just gives up on applying a patch because it cannot find a solution to the barriers.
This irresolute patching situation is not new to IT, but the impact of a possible adverse effect from an unpatched system has increased due to the EU General Data Protection Regulation (GDPR). This regulation significantly increases penalty levels for breaches. Even without it, the cost of a single breach can exceed US $50 billion.10
There is no miracle solution. Moving-everything-to-the-cloud solutions are just attempting to transfer this problem to the cloud provider. In addition to other cloud concerns, cloud providers have the same systems as enterprises with in-house infrastructures and must address the same patching issues. It should be kept in mind that real-life cloud provider contracts rarely, if ever, actually transfer the security risk to the cloud provider. Furthermore, cloud solutions typically address commodity software. If an enterprise uses custom software, which typically involves complex specialized applications, such as supervisory control and data acquisition (SCADA) systems, to control plant machinery, then it is very unlikely that the cloud is an option at all.
Another problem can be with patch monitoring tools that give conflicting reports regarding patch status, i.e., one tool may report that the system is missing a patch, but another tool may consider the system fully patched, which can result in false negatives or false positives.11
Solution I: High-Level Actions
Auditors who encounter the patching problem, i.e., unpatched software that cannot be patched due to one of the reasons described previously, cannot be satisfied with leaving systems vulnerable, but also cannot recommend halting production. Although IT cannot solve the problem alone, the enterprise can do something about patching.12
The issue must be brought to the attention of senior management so that it is easy for them to understand the potentially very serious risk that the enterprise is not addressing satisfactorily. The enterprise should consider the issues of support and vendor responsiveness to patching when a new application is planned. Some vendors require a support contract that explicitly covers patching. Vendors may demand very high fees for patching if it is not part of a support contract. These costs should be reviewed when a decision is made to buy or upgrade a new system.
Solution II: Controls
Implementing the following controls in patch management can help to alleviate the patching problem:
- Implement organizational requirements—The enterprise must have a responsible person or, ideally, unit that monitors patching. An architectural map and a categorization of systems with respect to criticality and exposure are also important. For example, a perimeter may be defined so that systems that are directly accessed from outside of the enterprise, e.g., Internet, can be identified because these may be the most exposed systems and those most in need of patching, barring insider attacks. Many large enterprises have numerous IT systems, and recording and keeping track of them are not simple tasks. A simple check is whether all responding IP addresses in the enterprise network are accounted for, i.e., known and classified. It is essential to not only know the systems that the enterprise is employing, but to also understand their criticality, exposure, protection needs and dependencies, i.e., interconnected or dependent systems, for example, a database or application running on top of an operating system.
- Monitor and assess—Regular scans of enterprise systems and patch versions are essential. Tools for these scans are widely available, but administrators must ensure that these tools are kept up-to-date. Typically, authenticated scanning is used, i.e., the scanner has access to information about system parameters that is not immediately available to an external attacker. An example parameter is the Java version, even if Java is not exposed to someone accessing the system from the outside (e.g., running a Java application server).
The reliability of these tools must also be assessed on a regular basis, because different tools or even versions of the same tool may produce different results.13 Patch monitoring results from one tool that can be cross-checked with a different tool. The end results of the scans must be assessed regarding their criticality, e.g., critical, major, medium or low. Some specialized systems and applications may have operating systems and/or environments that are not known by the scanning tools and, therefore, cannot be scanned. For such systems, penetration testing can be used to assess their vulnerability status or other mitigating measures can be taken, such as monitoring inbound and outbound traffic, if feasible. - Initiate action—Based on the criticality assessment, contacts should be initiated with affected interconnected or dependent resources and applications to investigate critical patch compatibility. The compatibility answer may take time. If a resource or application is not compatible, the enterprise should investigate production changes that can make the resource or application compatible. For example, if an operating system or programming environment patch is incompatible with a database or application, the solution may be to upgrade the database or application to the most recent version.
- Analyze the risk of unpatched critical systems—This requires developing an understanding of how the unpatched system may be exploited or may produce undesirable effects.
- Mitigate, test and monitor—Based on the risk analysis, the enterprise should take mitigating measures, test them and monitor their effectiveness. Examples of mitigating measures are detecting and disallowing actions that seek to exploit the known vulnerabilities.
- Specify vendor obligations in the contract—It is important to be aware of the patching issues and try to proactively specify (in the contract) vendor obligations for interconnected or dependent resources and applications. The contract can address the issue of promptly assessing patch compatibility and providing a compatible version if the resource or application is not compatible.
- Test nonguaranteed patches—Patches may be available, e.g., for the operating system, but their overall compatibility is uncertain, e.g., they cannot be guaranteed by the manufacturer to be compatible with the database or application. In such cases, the enterprise can perform its own tests, using a dedicated test environment, under conditions that are as realistic as possible. These tests can be performed even when the manufacturer guarantees compatibility, although this testing is usually not as comprehensive. If possible, testing is followed by a pilot or phased development, which is an additional testing period, so that the damage from a possible incompatibility or another patch-caused issue is limited.
Figure 1 illustrates the patch-management procedure.
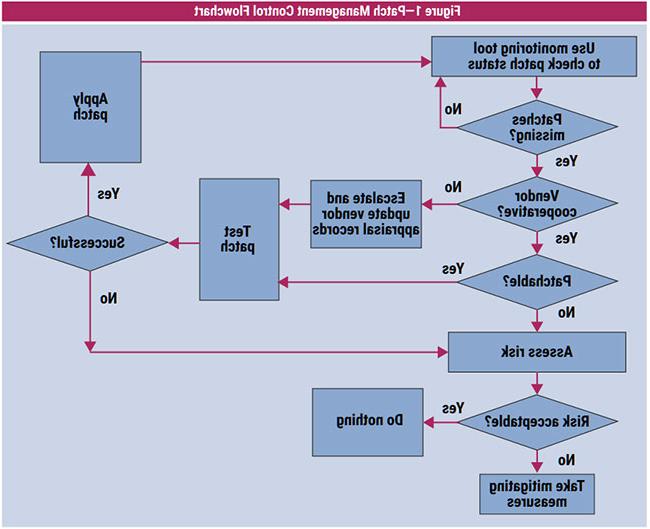
Following are the steps in the patch management flowchart:
- A monitoring tool runs periodically, typically daily or weekly depending on the number of systems, and typically at night so it does not interfere with the normal workload.
- Assuming the tool has been kept up-to-date, it detects missing patches.
- For every missing patch, the affected vendors are contacted. Affected vendors are the patch issuer and vendors of systems that are affected by the patch.
- The patch issuer normally makes the patch available, but the issuer may require a fee or some other contractual issue may arise.
- Affected vendors (e.g., the vendor for an application running on top of the operating system) also need to confirm if the patch is compatible with their system. Problems may arise due to out-of-support issues, vendor unresponsiveness, financial matters or contractual differences. Such problems are escalated to procurement or a similar function and eventually recorded to assess the ease of doing business with that vendor.
- If a patch is available, it is tested, regardless of whether all affected vendors guarantee compatibility. The only exception is if a vendor explicitly claims noncompatibility, and the case is treated as unpatchable. If the test is successful, then the patch is applied, normally in a pilot or phased approach, because testing can detect issues but cannot always guarantee a problem-free operation.
- If patching is not possible, the residual risk is evaluated. For example, the system in question may be Internet-facing or it may be in a highly protected zone, or its compromise may be of little or no consequence.
- Based on this evaluation, either the risk is accepted or mitigating measures are taken, as discussed in the following solution.
Solution III: Defense in Depth
Enterprises may be running numerous IT systems with different levels of support—some may be end-of-support but otherwise critical for production. Some of the systems may be unable to be patched or, for the immediate future, cannot be replaced due to the following reasons:
- High criticality
- Still functioning
- No fully satisfactory replacement
- Budget
Other systems may be unpatched for purely financial reasons, e.g., cost cutting, that also affect the vendor-support contracts.
If an enterprise has a system that cannot be patched or replaced for these reasons, the first line of defense, which is that all systems being always fully patched, is breached, and, hence, a second line of defense is needed. This second line of defense should ideally have the extra benefit of stopping zero-day attacks. The second line of defense should not be an excuse for doing away with the first line and then never patching, but it should not depend on the patch level of the systems in question.
Vendors are offering this type of behavior-based security solution, which is also known as advanced end point protection. For example, an agent may be installed on an unpatched system that detects when an application or exploit attempts to do something suspicious or damaging, such as a no-operation (NOP) slide, heap spray or just-in-time (JIT) spray and blocks that abnormal behavior or action. An example of behavior-based security solution is Traps.14
The main problem with these types of agent solutions, apart from possible technical issues relating to performance and availability, is that many vendors do not allow an agent from a third party (e.g., a security vendor) to run on their system in parallel to their own applications. If an administrator installs an agent on a vendor system without vendor consent, then the vendor can easily blame any problem on the agent and effectively void any warranty or support clause. The enterprise can end up with a secure but unusable or unsupported system.
If these defensive agent solutions cannot be installed on the unpatched systems, another solution is to install these or similar measures in the path to the unpatched systems. Depending on the risk that the enterprise is trying to guard against, this solution varies significantly in complexity. For example, if an enterprise is trying to defend against an outside attacker or exploit, behavior-based agents can be placed in the defined perimeter by employing methods such as web application firewalls (WAFs) with deep packet inspection (DPI) and considering performance issues.
Sandboxing is another possible solution if the defensive agent solutions cannot be installed on the unpatched systems.
Implementing the solution to intercept, check and block input (including possible exploits) somewhere in the path to the unpatched system depends on many factors, such as traffic and performance requirements. If prompt patching cannot be assured, alternative defense mechanisms should be considered. It should not be assumed that these solutions are simple or easy to implement; however, they should be considered as alternatives.
In addition to applying the solutions presented herein, an enterprise should review prompt detection and response carefully if unpatched systems are unavoidable. For example, although failover and replication are often suggested as a complete replacement for disaster recovery, they will be useless if the failover solution is also compromised, e.g., with ransomware. Monitoring the IT infrastructure for rogue activity grows in importance when critical unpatched vulnerabilities exist.
Conclusion
Patching is a very important security-related activity with risk too high to be ignored. Although, in theory, patching is straightforward and results in a purely compliance audit, in practice, patching is by no means a simple issue. A patch-management audit should consider and discuss alternative defenses if prompt patching is not possible.
Endnotes
1 Henderson, N.; “Equifax Says Unpatched Apache Struts Flaw Behind Massive Security Breach,” ITPro Today, 14 September 2017, www.itprotoday.com/patch-management/equifax-says-unpatched-apache-struts-flaw-behind-massive-security-breach
2 Weiss, J.; “Patch or Risk Being Breached: Tenable.io and the Verizon 2017 DBIR,” Tenable, 22 May 2017, www.tenable.com/blog/patch-or-risk-being-breached-tenable-io-and-the-verizon-2017-dbir
3 Wall, L.; T. Christiansen; R. L. Schwartz; Programming Perl, 2nd Edition, O’Reilly Media, USA, October 1996, p. 278-279
4 Saran, C.; “Meltdown and Spectre: To Patch or Not to Patch,” 18 January 2018, Computer Weekly, www.computerweekly.com/news/450433353/Meltdown-and-Spectre-to-patch-or-not-to-patch
5 Op cit Henderson
6 Op cit Weiss
7 Kerner, S. M.; “Unpatched Software and the Rising Cost of Breaches: Security Reports,” eWeek, 13 May 2016, www.eweek.com/security/unpatched-software-and-the-rising-cost-of-breaches-security-reports
8 Morgan, C.; “What to Do When You Can’t Patch a Vulnerability,” IKANOW, 23 May 2016, www.ikanow.com/what-to-do-when-you-cant-patch-a-vulnerability/
9 Grimes, R. A.; “Just Patch Java? Easier Said Than Done,” CSO, 16 January 2013, www.csoonline.com/article/2613513/security-management/just-patch-java-easier-said-than-done.html
10 Brewster, T.; “How Hackers Broke Equifax: Exploiting a Patchable Vulnerability,” Forbes, 14 September 2017, www.forbes.com/sites/thomasbrewster/2017/09/14/equifax-hack-the-result-of-patched-vulnerability/
11 Simsay, J.; “Is It Patched or Is It Not?” SANS Institute Information Security Reading Room, www.sans.org/reading-room/whitepapers/auditing/patched-not-35912
12 Op cit Morgan
13 Ibid.
14 Palo Alto Networks, “Traps: Advanced Endpoint Detection,” Traps Datasheet, 2015, www.paloguard.com/datasheets/endpoint-protection.pdf
Spiros Alexiou, Ph.D., CISA, CSX-F, CIA
Has been an IT auditor for a large European enterprise for the last 12 years. He has more than 24 years of experience in IT systems and has written numerous sophisticated computer programs. Alexiou can be reached at spiralexiou@gmail.com.