
With sensitive data residing everywhere and the breach epidemic growing, the need for advanced data security solutions has become even more critical. Compliance with regulations such as the EU General Data Protection Regulation (GDPR), Payment Card Industry Data Security Standard (PCI DSS), US State of California Consumer Privacy Act (CCPA), and the US Health Insurance Portability and Accountability Act (HIPAA) is driving the need for de-identification of sensitive data. It is important to discuss the similarities and differences between popular data protection techniques that can help in compliance with GDPR, CCPA and practical use in hybrid computing environments.
Some major aspects of the newer impactful rules in GDPR and CCPA are reviewed herein. CCPA is not simply a US version of GDPR. CCPA is more prescriptive than GDPR, including the scope of application, nature, extent of collection limitations and rules concerning accountability. CCPA also introduces a broad definition of what constitutes personal information.
New privacy regulations are emerging worldwide, from the US state of California to Brazil to India. Standards for data protection are also becoming more stringent according to Forrester’s Global Map of Privacy Rights and Regulations, 20191 (figure 1). In 2018 alone, the European Union began enforcing GDPR, California adopted the CCPA, and Brazil passed a comprehensive data protection regulation similar to GDPR. Other US states are following the example set by California. The New York Privacy Act was introduced in 2019. Other countries are moving ahead with privacy initiatives as well. India is in the process of passing “a comprehensive data protection bill that would include GDPR-like requirements.”2 Japan is ready to implement changes to domestic legislation to strengthen privacy protection in the country.3 Finland has implemented a very strict regulation that prevents organizations from using personally identifiable information (PII) of children under the age of 13 and gives regulators more powers to penalize enterprises for noncompliance.4

Privacy Regulations Have Global Impact
Sixty-eight percent of US organizations are expected to spend between US$1 million and US$10 million to meet GDPR requirements, and 9 percent of US organizations will spend more than US$10 million. In addition to GDPR, many other countries in and outside of the European Union have local privacy regulations.5 Besides GDPR, many EU countries and other countries have local privacy regulations, according to figure 1.
Data Protection for EU Cross-Border Data Protection Laws
A major bank performed a consolidation of all European operational data sources. This meant protecting PII in compliance with cross-border data protection laws in different European countries. In addition, the bank required access to Austrian and German customer data to be restricted to only people in each respective country. The primary challenge was to protect PII to the satisfaction of EU cross-border data security requirements. This included incoming source data from various European banking entities and existing data within those systems, which would be consolidated at the Italian headquarters of the bank. Figure 2 illustrates the use of tokenization for data protection in this project.

This depersonalized data could be used to analyze occupations and salaries in a way that is GDPR compliant.
Personal Data vs. PII
There is personal data, and then there is PII:
- PII “is data that can be used to directly or indirectly identify a particular person. This consists of such data items as a person’s name, address, email address, or phone number. For example, John Doe, 27 First St., NY 12165.”6
- Personal data are “data about the person and contains PII data. For example, John Doe, 27 First St., New York, New York, USA 12165, occupation: bus driver, salary US$41,000.”7
Data protection solutions may need to consider protecting personal data and PII.8
Privacy Fines
British Airways was fined £183 million by the UK Information Commissioner’s Office (ICO) for a series of data breaches in 2018, followed by a £99 million fine against the Marriott International hotel chain.9 French data protection regulator the Commission nationale de l’informatique et des libertés (CNIL) fined Google €50 million in 2019.10 Some enterprises narrowly avoided a GDPR-scale fine, as their data incidents occurred prior to GDPR’s implementation date. Both Equifax and Facebook received the maximum fine possible—£500,000—as per the previous UK Data Protection Act 1998. In 2019, Facebook settled with the US Federal Trade Commission (FTC) over privacy violations, a settlement that required the social network to pay US$5 billion.11
A Phased Approach to GDPR
IBM introduced a framework that can help organizations comply with GDPR (figure 3).12
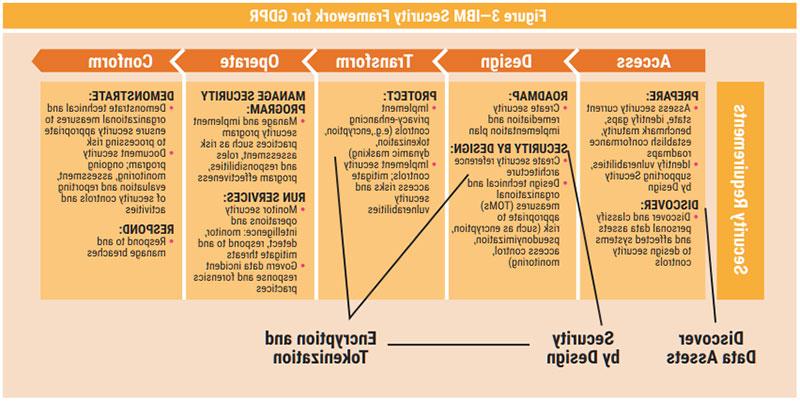
Phase 1 of the IBM framework (Prepare) involves assessing the organization’s specific situation; determining which data it collects, processes, stores and transfers that are subject to GDPR regulations; and then plotting a course to discover the data. Phase 2 (Design) is where the organization designs its GDPR approach, including the creation of a solid plan for data collection, use and storage. Phase 3 (Transform) involves transforming organizational practices by understanding that the data deemed valuable to the organization are equally valuable to the people they represent. The organization must also develop a sustainable compliance program and implement security, privacy and governance controls. Phase 4 (Operate) is where the organization is ready to operate its program. Stakeholders need to continually inspect data, monitor personal data access, test security, use privacy and security by design principles, and purge unneeded data. Phase 5 (Conform) is where the organization demonstrates compliance with necessary GDPR requirements such as “fulfilling data subject requests for access, correction, erasure and transfer data.”13
CCPA Redefines What Is Personal Data
The CCPA definition “creates the potential for extremely broad legal interpretation around what constitutes personal information, holding that personal information is any data that could be linked with a California individual or even a household.”14 CCPA states that “personal information” means information that identifies, relates to, describes, is capable of being associated with, or could reasonably be linked, directly or indirectly, with a particular consumer or household. This goes well beyond data that are obviously associated with an identity such as name, date of birth or social security number, which are traditionally regarded as PII. It is, ultimately, this indirect information such as product preference or geolocation data that is material, because it is much more difficult to identify it and connect it with a person than well-structured PII.
CCPA allows any California consumer to demand to see all the information an enterprise has saved on them as well as a full list of all the third parties with whom those data are shared. In addition, the CCPA allows consumers to sue enterprises if the privacy guidelines are violated, even if there is no breach.15
All enterprises that serve California residents and have at least US$25 million in annual revenue must comply with CCPA. In addition, enterprises of any size that “have personal data on at least 50,000 people or that collect more than half of their revenues from the sale of personal data,” also fall under the law.16 Enterprises do not have to be based in California or have a physical presence there to be subject to the CCPA. They do not even have to be based in the United States.
CCPA puts stricter guidelines on the collection and processing of personal information than the United States has seen previously.17 Under the CCPA, California residents will be able to:
- Know what personal information is being collected about them
- Access that information
- Know if their personal information is disclosed and to whom
- Know if their personal information is sold and have the right to opt out of the sale
- Receive equal service and price whether they exercise their privacy rights
CCPA and the Cloud
Any tools selected to help deal with CCPA will not only need to have full visibility into data stored across the entire heterogenous enterprise environment, but also ensure that access to this data is properly secured in accordance with CCPA mandates. If data are stored with cloud providers, the problem with visibility just gets worse. For example, employees may set up a file-sharing account to keep track of marketing or sales contacts.
GDPR vs. CCPA
CCPA is not simply a US version of GDPR; CCPA is more prescriptive than GDPR, including the scope of application, nature, extent of collection limitations and rules concerning accountability. Figure 4 compares GDPR rights vs. CCPA rights.
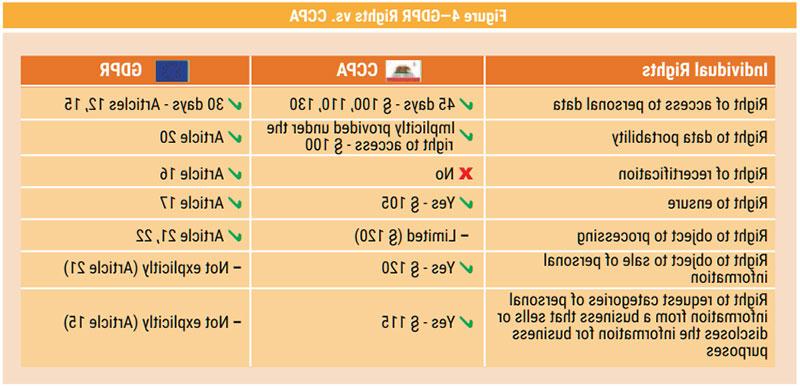
If an organization has already prepared for GDPR, it will not have to start over to prepare for CCPA, but that does not mean the organization has all the bases covered.18 There are differences in the scope of application, nature and extent of collection limitations, and also rules concerning accountability present different operational challenges for compliance. Figure 5 compares actions and fines in GDPR vs. CCPA.

Data Discovery and Classification
Data discovery and classification are critical in several regulations, including GDPR and CCPA. Data such as protected health information (PHI) or payment data that are subject to regulations such as HIPAA19 and PCI DSS20 can be found. Through discovery, the goal is to make sure that data do not exist in noncompliant locations. It is also important to verify that when data move, they do so in controlled and appropriate ways. Organizations face hurdles trying to understand their data. This includes discovering where the data are located and understanding what constitutes personal information (and, thus, data that fall under compliance requirements). It also includes considerations for how to classify (tag or label) of data.21 Many enterprises struggle here because today’s tools are siloed in their approaches (such as focusing on structured vs. unstructured data), limited in scope to specific data repositories or sources for discovery, and varied in their purpose for classification (identifying and categorizing data vs. tagging).
De-identification Techniques
Different de-identification techniques can be used for data protection that is in compliance with GDPR and CCPA. Some techniques will allow business operations on the protected data. Data minimization, that is, limiting the data that are directly relevant and necessary to accomplish a specified purpose at the earliest possible stage, typically makes the task of data de-identification easier. Each application requires the de-identified data to possess specific properties to accomplish their purpose. It is, therefore, necessary to preserve these properties after de-identification according to International Organization for Standardization (ISO)/International Electrotechnical Commission (IEC) standard ISO/IEC 20889 Privacy enhancing data de-identification terminology and classification of techniques,22 for example, this list of use cases involving protected data:
- Testing of software applications requires data that pertain to or emulate certain characteristics of the anticipated real data to achieve behavior under the test as close as possible to the conditions that will apply during use of the application.
- Statistical reporting includes collecting data at the level of individual data principals and generating statistical reports for a population on certain characteristics or events.
- Publishing of data for research purposes, also known as privacy-preserving data publishing (PPDP), often involves sharing sensitive data at the level of individual data principals.
- Performing data analytics on behalf of another party, also known as privacy-preserving data mining (PPDM), requires the transfer of data at the level of individual data principals and statistical data.
- Accessing and processing sensitive, truthful, unencrypted data at the level of individual data principals by authorized internal parties in data centers.
- Linking data to their corresponding data principal in certain cases by specially appointed parties.
Pseudonymization Techniques
The term pseudonymization refers to a “category of de-identification techniques that involves replacing a data principal’s identifier (or identifiers) with indirect identifiers specifically created for each data principal.”23 As such, pseudonymization is a technique that enables linking of associated records from different data sets without revealing the identities of the data principals.
Within two years, most of today’s cybersecurity technologies will be obsolete.24 The best course of action is to constantly innovate.
Tokenization
Tokenization solutions work with a high level of transparency with different applications and database technologies, provide consistent data across comprehensive application landscapes and include advanced security functionality and scale to very large volumes (production size).25 Tokenization is a process by which a surrogate value, called a token, replaces the primary account number (PAN) and, optionally, other data.26
Election Systems Inc. needs a way for its customers to pay for products online over the Internet using a web browser. They implemented tokenization via payment application using a vault-based tokenization (VBT) approach, hosted in a private cloud that reduces the PCI DSS scope and reduces the company’s on-premises attack surface to enable integration with several payment processors. An on-premises vaultless tokenization (VLT) would create a larger cardholder data environment and increased attack surface. The company is now not locked into a single processor or third party via the centralized private cloud vaulting of payment tokens. With this solution, the company’s settlement applications and call center applications are still in PCI DSS scope and can access tokens and any payment transaction details when needed.
An example company is using VLT of PII data for GDPR compliance and PI data for CCPA compliance in its data warehouse to support high-volume performance, avoiding any remote access to a database vault. This on-premises VLT tokenization approach can be more than 10 times faster than format-preserving encryption (FPE) or a VBT.
Format-Preserving Encryption
FPE is a method of transforming data that are formatted as a sequence of symbols in such a way that the encrypted form of the data has the same format, including the length, as the original data. FPE facilitates the de-identification or pseudonymization of sensitive information and the retrofitting of encryption technology to legacy applications where a conventional encryption mode is not feasible.27 US National Institute for Standards and Technology (NIST) Special Publication (SP) 800-38G was published in March 2016 to specify and approve the FF1 and FF3 methods for FPE.28
FPE provides protection for data in storage or when processed and makes the protected data useful in business processes for operations on PII, PI and payment card industry (PCI) data. FPE is suitable for deployment on-premises and in public or private clouds. Central processing unit (CPU) impact with FPE is typically 10 times more than Advanced Encryption Standard (AES) encryption.
The company decides to use FPE to encrypt its sensitive client data before sending them to the cloud-based Salesforce.com site. This approach is highly transparent to most functions in Salesforce.
Homomorphic Encryption
Homomorphic encryption (HE) is emerging as a data protection option when operations on encrypted data fields are required to be performed by untrusted parties, for example, in any distributed system or public cloud deployments.
Figure 6 illustrates HE when used in secure multi-party computation (Secure MPC). HE allows encrypted data to be processed without disclosing clear text. Fully homomorphic encryption schemes, which enable both multiplication and addition operations on encrypted data, are currently still inefficient in practical settings. Microsoft ElectionGuard, a free open-source software development kit (SDK), is an example of use of HE, which allows mathematical procedures such as counting votes to be done while keeping people’s actual votes fully encrypted.29

An example organization, Election Systems Inc., is developing and selling election support software applications globally. In the core use case in the election process, the voter is given a tracking code that, when voting is complete, will be entered into a website to confirm their vote was counted and not altered. The website will not display any voter’s actual votes. This tracking code enabled by HE ensures that voters can independently verify with certainty that their votes were counted and not altered. This also enables voting officials, the media or any third party to use a “verifier” application to similarly confirm that the encrypted vote was properly counted and not altered. This use of HE can enable end-to-end verifiable elections.
SINCE MASKING IS A ONE-WAY PROCESS AND NOT REVERSIBLE, IT MAY BE SUITABLE IN ANALYTICAL SYSTEMS AND FOR APPLICATION TEST ENVIRONMENTS, BUT TYPICALLY NOT FOR OPERATIONAL TRANSACTION SYSTEMS.
Masking
With masking, there is no encryption solution to revert the data to their original state. The term masking refers to a de-identification technique that involves potentially stripping out some or all of the additional remaining identifying attributes for all records in the data set. However, “removing a portion of a direct identifier so that it is no longer a direct identifier, but still a unique identifier is considered to be a pseudonymization technique.”30 After masking has been performed, typically additional de-identification techniques are applied to the data set.31
Since masking is a one-way process and not reversible, it may be suitable in analytical systems and for application test environments, but typically not for operational transaction systems. This is suitable for any cloud or on-premises deployment model.
Election Systems Inc. is masking PII and PI data in the dev/test systems as a one-way de-identification that is highly transparent to applications and databases. The concern is that the company’s masking approach needs to be re-evaluated frequently to verify that the inference risk is not increasing due to the availability of addition of public databases. Implementing the periodic cleanser filter process32 in differential privacy (DP) and K-Anonymity (KA) could help with this issue.
Hash Functions
Various techniques can be used to create pseudonyms. The choice of technique is based on factors such as the cost of creating the pseudonym, the collision-resistance factor of a hash function (i.e., the probability of two inputs hashing to the same output), and the means by which the data principal can be re-identified for the purposes of a controlled re-identification.33
A good hash function satisfies two basic properties:
- It should be very fast to compute.
- It should minimize duplication of output values (collisions).
Hash functions rely on generating favorable probability distributions for their effectiveness, reducing access time to nearly constant.
A hash function takes an input key, which is associated with a datum or record, and uses it to identify it to the data storage and retrieval application. The keys may be fixed length, such as an integer, or variable length, such as a name. In some cases, the key is the datum itself. The output is a hash code used to index a hash table holding the data or records, or pointers to them.34
A hash function is a one-way function that is not preserving the data type or length of the input value.
The most often used hash functions are SHA-1 and SHA-256, which produce 160- and 256-bit hashes, a binary long string expressed as 40 and 64 characters, respectively. Since hashing is a one-way process and is not reversable, it may be suitable in systems to verify the identity or integrity of data values and is typically not useful for data protection in operational transaction systems.
Cryptographic hash functions are specified in ISO/IEC 10118-3:2018 IT Security techniques—Hash-functions—Part 3: Dedicated hash-functions.35 NIST has approved hash algorithms36 in several documents, including two US Federal Information Processing Standards (FIPs): FIPS 180-4, Secure Hash Standard37 and FIPS 202.38 FIPS 180-4 specifies seven hash algorithms: SHA-1 (Secure Hash Algorithm-1) and the SHA-2 family of hash algorithms: SHA-224, SHA-256, SHA-384, SHA-512, SHA-512/224 and SHA-512/256.39
FIPS 202 specifies the new SHA-3 family of permutation-based functions as a result of the “SHA-3” Cryptographic Hash Algorithm Competition. FIPS 202 specifies four fixed-length hash algorithms: SHA3-224, SHA3-256, SHA3-384 and SHA3-512; and two closely related, extendable-output functions (XOFs): SHAKE128 and SHAKE256.40
Formal Privacy Measurement Models
A formal privacy measurement model is useful for compliance with GDPR and CCPA since it can demonstrate the level of privacy applied to data and is “an approach to the application of data de-identification techniques that enables the calculation of re-identification risk and, in some cases, provides mathematical guarantees against re-identification risk.”41
Differential Privacy
Figure 7 illustrates DP where responses to queries are only able to be obtained through a software component, or middleware, known as the “curator.” This approach is used by Apple and Google to limit the long-term storage of data related to individuals by periodically aggregating the detailed records.


DP essentially “guarantees that the probability that any data principal suffers privacy loss exceeding is bounded by a defined factor.”42
Mechanisms that follow the server model for DP typically preserve data in an unmodified form in a secure database. With DP in a local model, the entity receiving the data can reduce the risk locally instead of at the server level. The local model is useful when the entity receiving the data is not necessarily trusted by the data principals, or if the entity receiving the data is looking to reduce risk and to practice data minimization.
K-Anonymity Model
Figure 8 illustrates the KA model, which ensures that groups smaller than K individuals cannot be identified. Queries return at least K number of records. KA is a formal privacy measurement model that ensures that for each identifier there is a mapping equivalence class containing at least K records.43, 44, 45
Some of the de-identification techniques can be used either independently or in combination with each other to satisfy the KA model.
L-Diversity and T-Closeness
L-diversity is an “enhancement to K-anonymity for data sets with poor attribute variability.”46 It is designed to protect against deterministic inference attempts by ensuring that each equivalence class has at least L well-represented values for each sensitive attribute. L-diversity is suitable for privacy for any deployment model. T-closeness is an “enhancement to L-diversity for data sets with attributes that are unevenly distributed, belong to a small range of values, or are categorical.”47
Election Systems Inc. is using a data analytics application and needs to comply with GDPR and CCPA and reduce the risk of identifying individuals by using DP to aggregate individual records and the KA model to avoid identifying groups smaller than K individuals.
The company is masking PII and PI data in the dev/test systems as one-way de-identification that is highly transparent to applications and databases. The concern is that its masking approach needs to be re-evaluated frequently to verify that the inference risk is not increasing due to the availability of additional public databases. Implementing the periodic cleanser filter process in DP and KA can help with this issue.48
The Disappearing Data Center
When organizations store data in a public cloud, they do not have direct control over the data. Many executives may assume that, by moving to the public cloud, the cloud provider is going to protect their data automatically. That is not the case. The principal security challenge of hosting is keeping data from administrators and different hosted user communities separate. The simplest way to do this is to create physically separate systems for each hosted community. The disadvantage of this approach is that it requires a separate computer with separately installed, managed and configured software for each hosted user community. This provides little in the way of economies of scale to a hosting company.
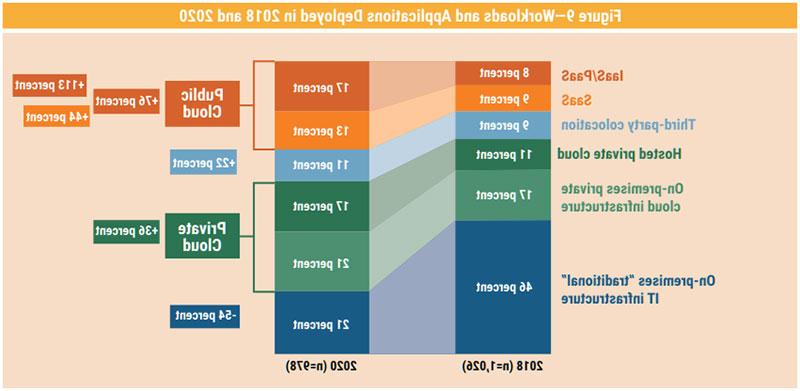
Workloads and applications are moving to cloud as illustrated in figure 9.49
Cloud Computing Models
Though cloud computing is a popular concept, there are various similar, but slightly different definitions of it. Deployments on-premises, in public or private cloud models, can be clarified by NIST SP 800-14550 covering definitions of cloud computing. This report provides clarification for qualifying a given computing capability as a cloud service by determining if it aligns with the NIST definition of cloud computing, and for categorizing a cloud service according to the most appropriate service model Software as a Service (SaaS), Platform as a Service, (PaaS) and Infrastructure as a Service (IaaS), as illustrated in figure 10.51

A Risk-Adjusted Computation Model
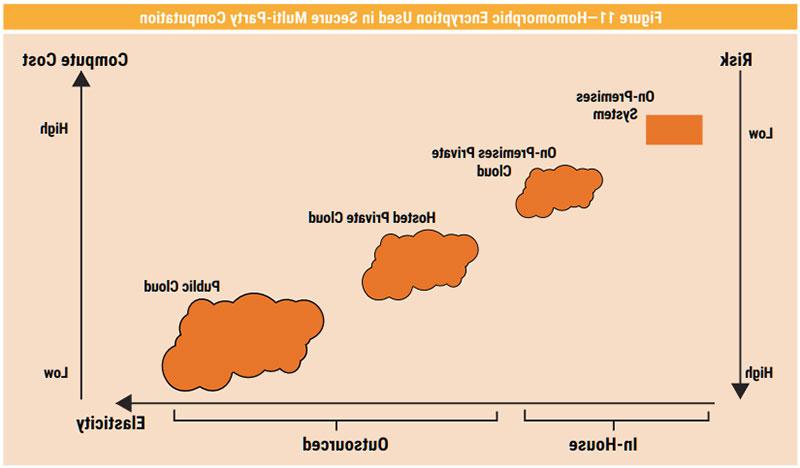
Risk-adjusted computation can provide SoD and balance risk and operational needs by deploying application components and data storage across on-premises and in the public or private cloud. A risk-adjusted computation model can provide SoD and balance requirements between security and operational needs and optimize the deployment of computation and data storage to separate systems on-premises or in public or private cloud. Tokenization, encryption processes and key management can be segmented and isolated in a separate private cloud service that avoids exposure of encryption keys and security control processes in on-premise or public clouds that are hosting business data.
Figure 11 compares suggested levels of risk and operational aspects such as computation cost and elasticity when deploying on-premises vs. outsourced deployment. The model suggests that different system components, application components or databases should be deployed on different platforms depending on risk level and operational aspects for each system component.
Protect Data Before Sending to the Cloud
Sensitive data can be encrypted or tokenized in a gateway before being sent to the cloud, avoiding exposure of encryption keys and security control processes on premises. An on-premise cloud-access security broker (CASB) or cloud-based software that sits between cloud service users and cloud applications monitors all activity and enforces security policies. A CASB can offer a variety of services including, but not limited to, monitoring user activity, warning administrators about potentially hazardous actions, enforcing security policy compliance, and automatically preventing malware.52 CASBs that deliver security must be in the path of data access, between the user and the cloud. Architecturally, this might be achieved with proxy agents on each end-point device or in agentless fashion without requiring any configuration on each device.53
Comparing Different Data Protection Techniques
Tokenization and FPE encryption can be highly transparent to most business processes and databases and support most operations on PII. HE is emerging as a data protection option when operations on encrypted data fields are required to be performed by untrusted parties, for example, in any distributed system or public cloud deployments.
With hashing and masking, there is no encryption solution to revert the data to their original state, and it limits the applicability in operational transaction systems. DP can reduce risk by practicing data minimization, and the KA model ensures that groups smaller than K individuals cannot be identified. These approaches are useful for test systems and analytical applications.
DIFFERENT BUSINESS USE CASES CAN IMPLEMENT A COMBINATION OF COMPUTATION AND DATA STORAGE ON-PREMISE OR IN A PUBLIC OR PRIVATE CLOUD.
Election Systems Inc. implemented tokenization using a VBT approach, hosted in a private cloud that reduced the PCI DSS scope and reduced its on-premise attack surface to enable integration with several payment processors. The company decided to use FPE to encrypt its sensitive client data before sending it to the cloud-based Salesforce.com. It is using VLT in its data warehouse to support high-volume performance. It is using a data analytics application and needs to comply with GDPR and CCPA to reduce the risk of identifying individuals by using DP.
The company is masking PII and PI data in the dev/test systems as a one-way de-identification that is highly transparent to applications and databases. The concern is that its masking approach needs to be reevaluated frequently to verify that the inference risk is not increasing due to the availability of additional public databases. Implementing the periodic CFP in DP and KA could help with this issue.
The examples in figure 12 illustrate tokenization and encryption deployed in different configurations on-premises, in public and private clouds, to balance risk and operational aspects. Different business use cases can implement a combination of computation and data storage on-premise or in a public or private cloud. Each use case can split up its operation between the different computing models.

Figure 12 illustrates common use cases in enterprise systems and an example of a system using homomorphic encryption. In three of the applications, encryption, key management and tokenization are isolated in a separate private cloud.
Conclusion
Identity theft is constantly increasing at an alarming rate, but the power of evolving data privacy models provides hope. It is important to have formal privacy models that can mathematically be evaluated when discussing data security and privacy in an informed effort.
The type of privacy regulations that impacted the business and technology landscape in Europe 40 years before impacting the United States gave the United States 40 years of “freedom to innovate” in business and technology before the European privacy regulations started to restrict the use of data. It is possible that these new regulations will spur innovation, as necessity is the mother of invention.
Many organizations are ignoring the fact that reevaluating the privacy of de-identified data should be an ongoing process that needs to reevaluate the attack scenarios each time additional data becomes available from different sources. CCPA gives enterprises a wake-up call about the issue of identifying individuals via data inference.
With the approach discussed, sensitive data, encryption keys and security control processes can be separated and isolated from on-premises systems and public cloud platforms. This approach can give a higher level of control for the most critical components of a security system when utilizing public cloud. Sensitive data can also be encrypted or tokenized before sending it to the cloud, by using a cloud-access security broker or by integrating data protection logic at the web server level.
Endnotes
1 Forrester, Forrester’s Global Map of Privacy Rights And Regulations, 2019, USA, 24 June 2019
2 Brown, C. T.; J. M. Casanova; C. Fonzone; C. F. Kerry; W. R. M. Long; G. Malhotra; “India’s New and Substantial Draft Data Privacy Bill,” Lexology, 24 September 2018, http://www.lexology.com/library/detail.aspx?g=47996e6e-330e-4a95-a071-3db53c630722
3 European Commission, “European Commission Adopts Adequacy Decision on Japan, Creating the World’s Largest Area of Safe Data Flows,” 23 January 2019, http://europa.eu/rapid/press-release_IP-19-421_en.htm
4 International Association of Privacy Professionals (IAPP), “Finland’s Revamped Data Protection Act Now in Effect,” Europe Data Protection Digest, 3 January 2019, http://iapp.org/news/a/finlands-revamped-data-protection-act-now-in-effect/
5 Op cit Forrester
6 Welch, R. ; “GDPR and Tokenizing Data,” TDWI, 6 June 2018, http://tdwi.org/articles/2018/06/06/biz-all-gdpr-and-tokenizing-data-3.aspx
7 Ibid.
8 Ibid.
9 IT Pro, “What Is GDPR? Everything You Need to Know, From Requirements to Fines,” 11 March 2020, http://www.itpro.co.uk/it-legislation/27814/what-is-gdpr-everything-you-need-to-know
10 Ibid.
11 Price, E.; “The EU Could Hit Facebook With Billions in Fines Over Privacy Violations,” Digital Trends, 12 August 2019, http://www.digitaltrends.com/social-media/facebook-gdpr-decision/
12 Utsler, J.; “IBM Framework Helps Clients Prepare for the EU’s General Data Protection Regulation,” 1 March 2018
13 Ibid.
14 BigID, “PI vs. PII: How CCPA Redefines What Is Personal Data,” 4 November 2019, http://bigid.com/ccpa-redefines-pii/
15 Korolov, M.; “California Consumer Privacy Act [CCPA]: What You Need to Know to Be Compliant,” CSO, 4 October 2019, http://www.csoonline.com/article/3292578/california-consumer-privacy-act-what-you-need-to-know-to-be-compliant.html
16 Ibid.
17 International Association of Privacy Professionals, “Trust the IAPP for Actionable Information on the California Consumer Privacy Act,” http://iapp.org/l/ccpaga/?gclid=EAIaIQobChMI-cnYtffG5QIVIueGCh09Cw56EAAYBCAAEgIEp_D_BwE
18 Wireweel, “GDPR vs. CCPA and the Impact on Your Data Privacy Operations”
19 Sweeney, L.; “Data Sharing Under HIPAA: 12 Years Later,” Workshop on the HIPAA Privacy Rule’s De-Identification Standard, Washington DC, USA, 8–9 March 2010
20 Payment Card Industry Security Standards Council (PCISSC), Tokenization Product Security Guidelines, Version: 1.0, April 2015, http://www.pcisecuritystandards.org/documents/Tokenization_Product_Security_Guidelines.pdf?agreement=true&time= 1570880509645
21 Ibid.
22 International Organization for Standardization (ISO)/International Electrotechnical Commission (IEC), ISO/IEC 20889:2018, Privacy enhancing data de-identification terminology and classification of techniques, http://www.iso.org/standard/69373.html
23 IBM, “GDPR Data Privacy Regulation,” http://www.ibm.com/security/privacy?p1= Search&p4=p50370571527&p5=e&cm_mmc= Search_Google-_-1S_1S-_-WW_NA-_-gdpr_e&cm_ mmca7=71700000061027927&cm_mmca8=kwd-2448790569&cm_mmca9=EAIaIQobChMI2Pyq3oDZ5wIVmY7ICh0Mlw8nEAAYAyAAEgLL_PD_BwE&cm_mmca10=405864114883&cm_mmca11= e&gclid=EAIaIQobChMI2Pyq3oDZ5wIVmY7ICh0Mlw8nEAAYAyAAEgLL_PD_BwE&gclsrc=aw.ds
24 Op cit PCISSC
25 7WData, “GDPR and Protecting Data Privacy With Cryptographic Pseudonyms,” 12 April 2018, http://www.7wdata.be/logistics-industry/gdpr-and-protecting-data-privacy-with-cryptographic-pseudonyms/
26 Op cit PCISSC
27 International Organization for Standardization/International Electrotechnical Commission, ISO/IEC 20889, Privacy enhancing data de-identification terminology and classification of techniques, http://webstore.iec.ch/preview/info_isoiec20889%7Bed1.0%7Den.pdf
28 Op cit International Association of Privacy Professionals, “Trust the IAPP for Actionable Information on the California Consumer Privacy Act”
29 Burt, T.; “ElectionGuard Available Today to Enable Secure, Verifiable Voting,” Microsoft, 24 September 2019, http://blogs.microsoft.com/on-the-issues/2019/09/24/electionguard-available-today-to-enable-secure-verifiable-voting/
30 Op cit ISO/IEC 20889
31 Ibid.
32 Ibid.
33 Ibid.
34 Ibid.
35 International Organization for Standardization/International Electrotechnical Commission, ISO 67116, IT Security techniques— Hash-functions—Part 3: Dedicated hash-functions, http://www.iso.org/standard/67116.html
36 Federal Information Processing Standards, “FIPS 180-4, Secure Hash Standard,” USA, August 2015, http://csrc.nist.gov/publications/detail/fips/180/4/final
37 Ibid.
38 Federal Information Processing Standards, “FIPS 202, SHA-3 Standard: Permutation-Based Hash and Extendable-Output Functions,” USA, August 2015, http://csrc.nist.gov/publications/detail/fips/202/final
39 Op cit Federal Information Processing Standards, FIPS 180-04
40 Op cit Federal Information Processing Standards, FIPS 202
41 Op cit ISO/IEC 20889
42 Dwork, C.; K. Kenthapadi; F. McSherry; I. Mironov; M. Naor; “Our Data, Ourselves: Privacy Via Distributed Noise Generation,” Proceedings of Eurocrypt 2006, Lecture Notes in Computer Science, vol. 4004, Springer-Verlag, Switzerland 2006, p. 486–503, http://link.springer.com/chapter/10.1007/11761679_29
43 Op cit ISO/IEC 20889
44 Samarati, P.; L. Sweeney; “Protecting Privacy When Disclosing Information: K-Anonymity and Its Enforcement Through Generalization and Suppression,” SRI International, 1998
45 Sweeney, L.; “K-Anonymity: A Model for Protecting Privacy,” International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, vol. 10, iss. 5, October 2002, p. 557–570
46 Op cit ISO/IEC 20889
47 Ibid.
48 Ibid.
49 Cloudvisory, “451 Research: Securing the Modern Cloud—Trends and Practices,” 23 May 2019, http://www.youtube.com/watch?v=Js_FrohxGDY&feature=youtu.be
50 National Institute of Standards and Technology, “NIST Releases Evaluation of Cloud Computing Services Based on NIST SP 800-145 (NIST SP 500-322),” USA, 23 February 2018, http://www.nist.gov/news-events/news/2018/02/nist-releases-evaluation-cloud-computing-services-based-nist-sp-800-145
51 Microsoft, “What Does Shared Responsibility in the Cloud Mean?” http://blogs.msdn.microsoft.com/azuresecurity/2016/04/18/what-does-shared-responsibility-in-the-cloud-mean/
52 Netskope, “What Is a Cloud Access Security Broker (CASB)?” http://www.netskope.com/about-casb
53 Ibid.
Ulf Mattsson
Contributed to the development of the Payment Card Industry Data Security Standard (PCI DSS) and American National Standards Institute (ANSI) ANSI X9. He also developed products and services when working at IBM, Protegrity and other technology companies in the areas of robotics, enterprise resource planning, data encryption and tokenization, data discovery, cloud application security brokers, web application firewalls, managed security services and security operation centers. Mattsson worked with data protection projects in several different countries, including compliance solutions for EU Cross Border Data Protection Laws. He is a regular speaker at international security conferences and has written a series of articles in the ISACA® Journal and ISSA Journal. He is an inventor who holds more than 70 US patents and is currently head of innovation at TokenEx. He can be reached at ulf@ulfmattsson.com.