
Data resilience has several vendor definitions, for example: maintenance of the availability of hosted production data,1, 2 the ability of data infrastructure to avoid unexpected disruptions,3 and a combination of the governance, operational and technical considerations involved in these efforts.4 The third definition is most closely aligned with true data resilience.
A non-vendor-related definition proposes that a resilient data system can continue to operate when faced with adversity that could otherwise compromise its availability, capacity, interoperability, performance, reliability, robustness, safety, security and usability (figure 1).5 It is not always clear what attributes of resilience—other than availability—are provided by a vendor’s product, and although availability is necessary, it is insufficient on its own for data system resilience.6
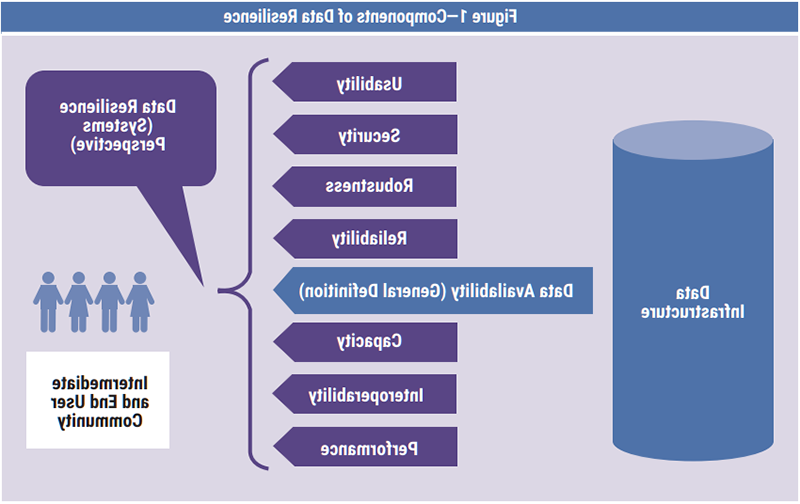
To understand data resilience, it is necessary to understand the impact of:7
- The failure to provide the critical capabilities and services the data system needs in the face of disruptions
- The disruption of the delivery of critical data capabilities
- The types and levels of harm imposed on organizational assets as a result of a data disruption
Practitioners with risk management experience will recognize that the identification of threats and vulnerabilities, and their impact, is part of good risk management. True data resilience is about maintaining the necessary qualities of an enterprise’s key data in the face of any types of adversity, wherever those data reside.
Toward a More Complete Picture of Data Resilience
Hosted production data availability is one type of adverse event or condition that can affect system resilience, with other examples indicated by area 1 in figure 2.8 Furthermore, the risk management element of resilient systems is highlighted by area 2. Area 3 is significant because it articulates the impact of the adversities. In practice, the terminology in figure 2 would reflect the particular system requiring resilience. For a data system, the adverse events and conditions would reflect the types of adversity that could affect data, and the assets would be the implications of actions taken given the adverse impact on data.
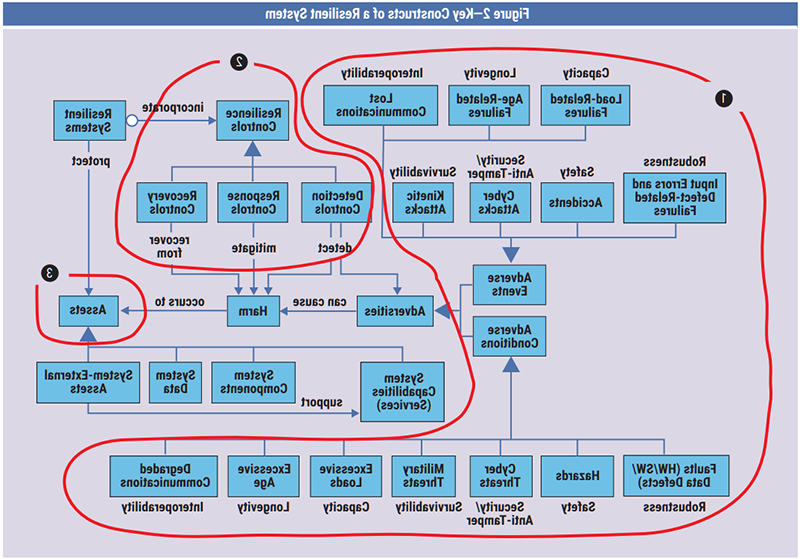
Source: Based on figures 1 and 2 from Firesmith, Donald; “System Resilience: What Exactly Is It?” SEI Blog, 25 November 2019, http://insights.sei.cmu.edu/sei_blog/2019/11/system-resilience-what-exactly-is-it.html.
Accessed: 25 December 2020. © 2020 Carnegie Mellon University, with special permission from its Software Engineering Institute; however, this publication has not been reviewed nor is it endorsed by Carnegie Mellon
University or its Software Engineering Institute.
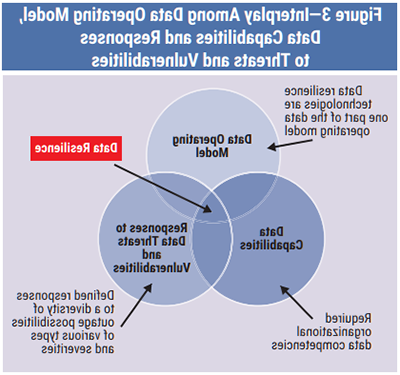
In particular, data resilience can be considered from at least two perspectives: a data operating model perspective and a data capabilities perspective.
Data Operating Model Perspective
Vendor-specific definitions of data resilience are
insufficient because technology is just one element
in an enterprise’s ability to fulfill its purpose with the
necessary continuity. Although availability, capacity,
interoperability, performance, reliability, robustness,
safety, security and usability may depend on
technology, there are other dimensions of the data
operating model, such as people, process,
governance and numerous other lesser-known
attributes, such as intellectual capital, that must be
considered. To be resilient, “a system must
incorporate controls that detect adverse events and conditions, respond appropriately to these
disturbances, and rapidly recover afterward,”9
all of which requires much more than the use
of technology.
True data resilience involves people. Just as a desired outcome may not be possible because the necessary data are not available, a desired outcome may be unobtainable because only particular individuals have certain data-specific knowledge that is not available when needed.
True data resilience also involves processes. For example, what happens if there is no defined process to enact technology-based risk control when it is needed? Someone needs to put the risk control plan into action, but with no predefined procedure, that will be done at this person’s discretion, with an unpredictable outcome and in an unpredictable time frame.
True data resilience involves governance as well. Even if a well-defined process exists, what happens if there is no clarity about who owns the process and who is responsible for executing it? If something goes wrong in the data factory, nobody may know who needs to take what action to address the calamity. Clear governance is an imperative.
Note that people are involved in two components of effective data resilience: for the availability of knowledge and for process ownership and execution. Both elements are necessary to ensure an appropriately structured and rapidly and correctly executed response to adversity.
 If they are not managed properly, people, process
and governance with a technology outage can be as
problematic as any other vulnerability. Not
recognizing and responding to this situation might
mean there is no quick recovery from adversity.
Instead, there will be risk with no clear response,
with no ownership of that response, followed by
chaotic and unpredictable actions and a time frame
that does not reflect a resilient system.
If they are not managed properly, people, process
and governance with a technology outage can be as
problematic as any other vulnerability. Not
recognizing and responding to this situation might
mean there is no quick recovery from adversity.
Instead, there will be risk with no clear response,
with no ownership of that response, followed by
chaotic and unpredictable actions and a time frame
that does not reflect a resilient system.
Data resilience is not an outcome of technology alone. It involves an interplay among the full data operating model, the enterprise’s data capabilities, and its defined responses to identified data threats and vulnerabilities (figure 3).
Data Capability Perspective
The ability to respond quickly to interruptions in
data capabilities and services is an important facet
of data resilience. Examples of these capabilities
include data governance, data quality management,
metadata management, master data management,
data lineage, data reconciliation, data forensics,
data certification (attestation), data discovery and
business intelligence.10
A failure in data capabilities can compromise any combination of the attributes listed in figure 1. Several examples illustrate the nature of data capability failures that could compromise resilience.
EVEN IF A WELL-DEFINED PROCESS EXISTS, WHAT HAPPENS IF THERE IS NO CLARITY ABOUT WHO OWNS THE PROCESS AND WHO IS RESPONSIBLE FOR EXECUTING IT?
A Reliability Example
Fit-for-purpose data require that all critical data
elements, master data and reference data meet
predefined quality thresholds for accuracy,
completeness, uniqueness and validity. If this
capability fails—a data quality outage—how can an
enterprise’s data be deemed reliable?
It is highly unlikely that data in this type of outage would be sent to regulators, given the presence of regulations such as the Basel Committee on Banking Supervision (BCBS) standard 239 and the International Financial Reporting Standard (IFRS) 17 for insurance. BCBS 239 was specifically introduced to address poor-quality data as one of the underlying reasons for inadequate financial crisis prevention.11 An enterprise would probably rather be late than wrong, even though both events would be regarded as serious shortcomings by regulators. Data resilience would have been compromised, and there would be no predictable time frame for a suitable response.
The London Inter-Bank Offered Rate (LIBOR) scandal had bad data at its roots, resulting in billions of US dollars in penalties paid by implicated banks.12, 13 Such a scandal would have resulted in the halting and reengineering of all associated processes and governance, temporarily compromising any resilience that might have been in place, in spite of the demonstrated undesirability of the old process.
A Security (and Privacy) Example
Data privacy capability is facilitated by privacy-enhancing
technologies (PETs), such as personally
identifiable information (PII) anonymization and
pseudonymization tools; processes; people; and
governance. A breakdown in any of these elements
can compromise an enterprise’s compliance with
privacy regulations (potentially leading to lawsuits)
and negatively impact its reputation. To address the
problem, the process involving personal data should be halted—a data privacy outage. Other unexpected
outages may occur because PETs are too
complex,14 potentially resulting in extended time
frames and, therefore, poor resilience.
Security measures must be in place to protect the enterprise’s key data: personal, health and other sensitive data such as financial and human resources (HR) information. If there is a breach, data-related activities at the point of the breach should be halted until the breach is addressed. The interruption of these regular processes could be defined as a data outage, indicating a lack of resilience. For example, the interval between the discovery of the Equifax data breach and its announcement was approximately three months,15 a time frame that does not easily meet the impacted parties’ expectations of resilience.
A Usability Attribute Example
Data artifacts (such as extracts, business intelligence
and reports, analytics, artificial intelligence [AI], and
machine learning [ML] outputs) should all be
accompanied by an appropriate certification or
attestation of the quality of the artifact, summarizing
its degree of reliability and, thus, the decision maker’s
level of confidence in basing a decision on the
artifact. If an incorrect decision is made because no
such information is available, the result can not only
negatively impact operations and cause reputational
damage but also halt the data process—a data
outage—until the shortcomings are addressed.
Indeed, BCBS 239 is about making data quality (the
input) reliable enough to ensure usable regulatory
reporting (the output).16
A Capacity Attribute Example
The most public example of data capacity being a
constraint on data resilience was Google’s recent
global outage, where the error was due to “lack of
storage space in authentication tools,” given an
unforeseen use case.17, 18 Although the outage
lasted only about six hours—arguably within the
bounds of resilience—it impacted major services
used by more than two billion enterprises and
individuals around the world, some of which
suffered the outage for nearly a full business day.19
For those users, six hours before recovery would
not be considered resilient.
Data Adversity + Harm Management = Data Risk Management
The effect of adversity on data capabilities can cause an enterprise considerable harm. This is especially true if the enterprise does not have the reliability, security, usability and capacity to quickly bounce back from adversity.
In risk management language, these resilience attributes can also be considered vulnerabilities. It is critical for enterprises to be able to identify and assess the individual vulnerabilities that can compromise their data resilience to be able to respond to their risk impact (figure 4). Effecting full-scope data resilience can, thus, readily be expressed as a data risk management goal.

Many think of data risk only in a cybersecurity sense. However, data risk can be defined as the potential for business loss due to not only data security issues but also poor data governance and poor data management over the data life cycle.20 Potential consequences include IT infrastructure compromise, financial losses and penalties, staff recovery costs, data center downtime, decreased organizational productivity, and a negative impact on brand value and reputation.21
It is important to mention that there are many other data risk factors, some of which are not directly associated with resilience, such as data sovereignty (ownership of data), data remanence (elimination of data traces after deleting files or from defunct devices) and data rot (corruption of data over time).22 Data rot is an interesting risk, highlighting the importance of data media maintenance and data transport validation (DTV), which is validating the accuracy of data transferred from one repository to another, for the movement of data between media.23
IN RISK MANAGEMENT LANGUAGE, THESE RESILIENCE ATTRIBUTES CAN ALSO BE CONSIDERED VULNERABILITIES.
Conclusion
What does data resilience really mean? Although it could be fatal if an enterprise were unable to recover from adversity related to data availability, even if the data were available, problems with any of the enterprise’s data capabilities, data quality or other operating model constructs could cause a disruption with lasting or even fatal consequences. Therefore, it is critical for an enterprise to identify the adversity types that could compromise its ability to deliver and ensure that appropriate responses are in place. In risk management language, it is all about identifying the data threats and vulnerabilities, understanding their impact, and implementing controls to ensure that those threats and vulnerabilities do not significantly compromise the enterprise in any way. In other words, data resilience is not only about deploying technology to ensure data availability. Likewise, it is not only about being cognizant of the risk factors inherent in the data operating model or in its data capabilities, although this will lead to greater data resilience than technology alone. Rather, true data resilience concerns the enterprise’s ability to perform effective risk management across the entire data ecosystem for a broad diversity of risk factors.
To learn more about data resilience, watch Pearce discuss his article in this video interview.
Endnotes
1 IBM, “Data Resilience”
http://www.ibm.com/support/knowledgecenter/en/ssw_ibm_i_73/rzarj/rzarjhacompdatares.htm
2 Fishman, N.; “Ensure Data Resilience,” IBM,
http://www.ibm.com/garage/method/practices/manage/ensure-data-resilience/
3 Cook, C.; “Balancing Data Resiliency With
Data Recovery,” Flexential, 17 July 2019,
http://www.flexential.com/resources/blog/balancing-data-resiliency-data-recovery
4 Data Resilience, “Data Resilience Is
Complicated,” http://www.dataresilience.com.au/
5 Firesmith, D.; “System Resilience: What Exactly
Is It?” Software Engineering Institute Blog,
Carnegie Mellon University, Pittsburgh,
Pennsylvania, USA, 25 November 2019,
http://insights.sei.cmu.edu/sei_blog/2019/11/system-resilience-what-exactly-is-it.html
6 Ibid.
7 Ibid.
8 Ibid.
9 Ibid.
10 The Data Administration Newsletter, “10 Data Management Capabilities That
Address Urgent Business Priorities,” 1 January
2012, http://tdan.com/ten-data-management-capabilities-that-address-urgent-business-priorities/15733
11 Voster, R. J.; “BCBS 239 Banking on Data,”
Compact, 2014, http://www.compact.nl/en/articles/bcbs-239-banking-on-data/
12 Rayburn, C. C.; The LIBOR Scandal and
Litigation: How the Manipulation of LIBOR Could
Invalidate Financial Contracts, vol. 17, University
of North Carolina (UNC) School of Law,
Chapel Hill, North Carolina, USA, and North Carolina Banking Institute, USA, 2013,
http://scholarship.law.unc.edu/ncbi/vol17/iss1/10
13 Redman, T. C.; “Libor’s Real Scandal: Bad Data,”
Harvard Business Review, 13 July 2012,
http://hbr.org/2012/07/libors-real-scandal-bad-data
14 Government of Canada, “Privacy Enhancing
Technologies—A Review of Tools and
Techniques,” Office of the Privacy
Commissioner of Canada, November 2017,
http://www.priv.gc.ca/en/opc-actions-and-decisions/research/explore-privacy-research/2017/pet_201711/
15 Fruhlinger, J.; “Equifax Data Breach FAQ:
What Happened, Who Was Affected, What
Was the Impact?” CSO, 12 February 2020,
http://www.csoonline.com/article/3444488/equifax-data-breach-faq-what-happened-who-was-affected-what-was-the-impact.html
16 Op cit Voster
17 Hern, A.; “Google Suffers Global Outage With
Gmail, YouTube and Majority of Services
Affected,” The Guardian, 14 December 2020,
http://www.theguardian.com/technology/2020/dec/14/google-suffers-worldwide-outage-with-gmail-youtube-and-other-services-down
18 Greiner, L.; “The Great 2020 Gmail Outage:
A Tale of Two Blackouts, and Lessons Learned,”
IT World Canada, 21 December 2020,
http://www.itworldcanada.com/article/the-great-2020-gmail-outage-a-tale-of-two-blackouts-and-lessons-learned/439924
19 Sky News, “Google Services Including Gmail
Hit by Serious Disruption,” 20 August 2020,
http://news.sky.com/story/google-services-including-gmail-hit-by-serious-disruption-12052892
20 Mesevage, T. G.; “What Is Data Risk
Management?” Datto, 7 May 2019, http://www.datto.com/library/what-is-data-risk-management
21 Ibid.
22 Spacey, J.; “10+ Types of Data Risk,”
Simplicable, 14 April 2017,
http://simplicable.com/new/data-risks
23 Pearce, G.; “Data Auditing: Building Trust in
Artificial Intelligence,” ISACA® Journal, vol. 6,
2019, http://h04.v6pu.com/archives
Guy Pearce, CGEIT
Has served on governance boards in banking, financial services and a not-for-profit, and as chief executive officer (CEO) of a financial services organization. He has taken an active role in digital transformation since 1999, experiences that led him to create a digital transformation course for the University of Toronto School of Continuing Studies (Ontario, Canada) in 2019. Consulting in digital transformation and governance, Pearce readily shares more than a decade of experience in data governance and IT governance as an author in numerous publications and as a speaker at conferences. He received the 2019 ISACA® Michael Cangemi Best Author award for contributions to IT governance, and he serves as chief digital officer and chief data officer at Convergence.Tech.