
The real-world rate of change affecting almost everything to do with data is what separates the theory of enterprise data resilience from its practice. Change is not only inherent in the dynamics of the problems to be solved with data, but also in the dynamics of a host of data-related activities and considerations: data sourcing, collection and categorization; data storage on-premises or in the cloud; data governance and its associated disciplines to ensure fit-for-purpose data; the types of analytics or artificial intelligence (AI) models used; and the model training applicable for insight development and decision-making.
Data can be affected by expected and unexpected changes in everything from hardware and software components to regulatory, sociopolitical and community requirements. Ultimately, it is how the enterprise plans for and reacts to change that determines the effectiveness of its data resilience strategy. Furthermore, the inevitability of change, or drift, means that even the most well-laid plan for enterprise data resilience must frequently be reviewed to ensure its effectiveness.
To understand the term data resilience, it is helpful to consider the evolution of the word data. It originated 380 years ago, but it took another 300 years for its modern meaning to take hold. In 1946, data were defined as the “transmittable and storable information by which computer operations are performed.”1 The word resilience originated at about the same time as the word data, back in the 1620s, and its definition has been constant. Resilience is the “act of rebounding or springing back.”2 An interesting conceptual basis for computation also originated in the 17th century. Wilhelm Leibnitz, a German mathematician, philosopher, scientist, and diplomat, held that the mind operates by ordinary physical processes, implying that mental processes could be performed by machines.3
Real-world data resilience can, thus, be defined as the ability (or set of processes) to transmit or store information in a manner that supports processing to rebound from an adverse event. There are multiple levels of data resilience, as shown in figure 1. In practice, data resilience encompasses more than the general commercial definition of the term,4 which addresses the role of cloud in data availability—a single dimension of data resilience.
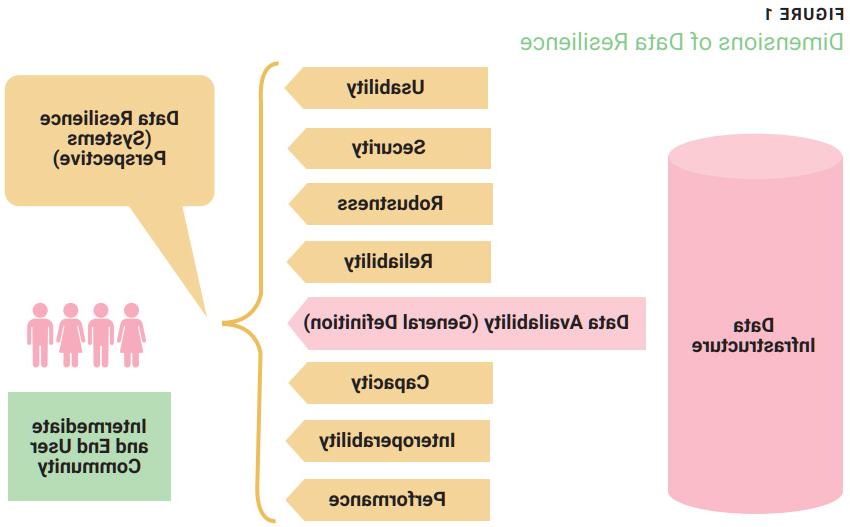
In this context, data resilience is also seen as a process that “represents the safeguards and validation of integrity of data that is utilized in the training of machine learning models.”5 This is represented by the usability dimension of data resilience in figure 1, and it leads not only to the intersection of AI and data governance, but also to the intersection of these two disciplines and data resilience, a process that is “fundamental to trustworthy AI.”6
AI, data governance and the cloud are, therefore, inextricably linked to data resilience. This strategic construct accentuates an emerging need for standards that better enable the link between these converging technologies and data resilience. Furthermore, recognizing that data are at the heart of each of these concepts means that the converged technologies need to be the focus of an organization’s data resilience strategy to best enable the role of data in the enablement of the organization’s enterprise strategy and in sustaining operational continuity.
Cloud Services
Cloud technologies introduced significant changes to the way computing is done in the 21st century. The cloud made almost any computing resource available on demand at a pace much faster than could ever be achieved on-premises, and with add-on services that would usually require a far more significant additional investment. For accountants, the reduction in capital expenditure for cloud computing resources vs. on-premises computing resources has been appealing. Still, if the cloud team’s skills are lacking, the cloud can present the enterprise with unexpected operating expenditures that erode any potential savings.7
Cloud services take many forms, such as Software as a Service (SaaS) for applications, Platform as a Service (PaaS) for application-hosting environments, Infrastructure as a Service (IaaS) for operating systems, and such recent additions as Mobile Backends as a Service (MBaaS) for web and mobile development and Function as a Service (FaaS) for event-driven remote procedure calls. Cloud service deployments take many forms. There are public clouds, private clouds, hybrid clouds and some less well-known deployment models. In the context of this discussion, AI could take the form of SaaS or PaaS.
Only 41 percent of EU organizations had adopted cloud technologies by 2021, and this was generally limited to email and data storage functionality.8 In general, cloud for business is yet to be mainstream in the European Union.9 This regional example highlights the challenges in making the case for the cloud’s perceived usefulness and ease of use (figure 2). Coincidentally or otherwise, the apparent alignment between some external variables driving cloud use compared to the dimensions of data resilience in figure 1 suggests data resilience activities may actually indirectly drive and accelerate cloud adoption (figure 3).

Source: Werner, L.; G. Burch; "Migrating to the Cloud: How the COVID-19 Pandemic Has Affected the IT Landscape," ISACA® Journal, vol. 1, 2022,
http://h04.v6pu.com/archives. Reprinted with permission

AI
AI encompasses technologies such as machine learning (ML), deep learning, natural language processing (NLP), robotics, expert systems, neural networks, computer vision, evolutionary computation and fuzzy logic.10, 11
There are two dominant schools of AI (figure 4). Symbolic AI, which has its foundations in the academic roots of the discipline that emerged in the 1950s, focuses on human readable rules and logic. Statistical AI (also known as connectionist or neural AI), with roots in the 1980s based on mathematical modeling,12 has become the dominant technology. Symbolic AI is a top-down approach seeking to “replicate intelligence by analyzing cognition independent of the biological structure of the brain,”13 while statistical AI is a bottom-up approach that creates “artificial neural networks in imitation of the brain’s structure.”14

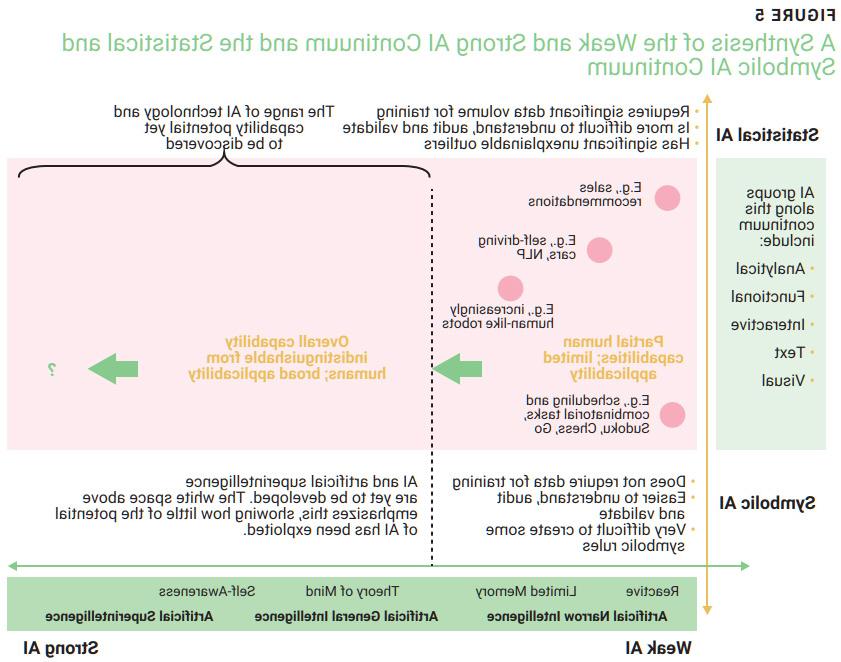
Another categorization of AI is whether it is deemed weak or strong (figure 4). Strong AI is generalizable and displays capabilities indistinguishable from that of humans,15 while weak AI replicates a specific human capability. This continuum highlights that not all AI is equal; the AI in a sales recommendation is not in the same class as the AI in a self-driving car. The most advanced position on the continuum shows how primitive AI still is; there is still a long way to go to realize processing capabilities indistinguishable from that of humans.
Strong statistical AI manages multiple use cases employing technologies such as clustering and association, while weak statistical AI tends to focus on a specific use case employing technologies such as classification.16 Most recent progress in AI has been made in the weak or applied form of statistical AI, where commercially viable smart systems show the most promise.17
From a governance perspective, symbolic AI is easier to audit than statistical AI, and symbolic AI is easier to understand and, therefore, to explain than statistical AI. From an audit and risk perspective, the Stanford University (California, USA) AI Index Report for 2021 indicates that most enterprises seemed unaware of or unconcerned with the risk associated with the technology, but, significantly, those that were concerned saw increased risk with respect to the explainability of AI outcomes.18 Explainability is a key component of privacy regulations such as the EU General Data Protection Regulation (GDPR), as it upholds the right to an explanation for any forms of data processing19 (including what AI gathers, processes or learns from personal data). Security and robustness, two dimensions of data resilience (figure 1), also make up part of the GDPR’s requirements for privacy.20
Statistical AI not only needs data of sufficient volume to train the AI structures, but it also might need data from different sources (on-premises or cloud) that may not have comparable levels of data management. Without suitable controls to ensure data consistency both intrasource and intersource, AI “is too risky to be trusted with consequential decisions.”21 Indeed, data governance and enterprise data management are critically important components of trusted AI.22
There are more granular categorizations for AI along both axes synthesized in figure 5. One divides the technology into four types of machines listed from weak to strong: reactive (e.g., chess computers—weak), limited memory (e.g., self-driving cars—weak), theory of mind (future build—strong), and self-awareness (future build—strong).23 Another categorizes AI along the symbolic-statistical axis with a bias toward statistical AI: analytic AI (e.g., sentiment analysis), functional AI (e.g., robots), interactive AI (e.g., chatbots), text AI (e.g., text recognition), and visual AI (e.g., augmented reality). Yet another categorization speaks of artificial narrow intelligence (i.e., all existing AI), artificial general intelligence (i.e., AI indistinguishable from humans) and artificial superintelligence (i.e., the most capable forms of intelligence).24 Any that require data must be subject to harmonized data governance to be deemed trustworthy.
From a technology risk management perspective, AI has been the subject of various cycles of hype and disillusionment over the last 60 years, with the disillusionment cycles of the 1970s and the late 1980s25 perhaps forgotten amid the current hype. However, there are signs of a new phase of disillusionment: The volume of AI deals has declined since the last peak in Q3 2019,26 retail AI dropped to a four-year low in 2020,27 the number of newly funded AI enterprises has been in decline since 201728 and enterprises that are investing seem to be spending more but getting less from AI.29
These trends have implications for the investment potential of AI and pose a technology risk for IT governance professionals to consider. Another risk is the possibility of AI model drift for most of the dimensions of data resilience.
Data Governance
The focus of data governance is largely on the decision rights and accountability for an organization’s data assets, with activities consisting of defining data roles and responsibilities, data policies, data processes and procedures, and data standards.30 In practice, data governance is closely related to data quality.31 Specifically, data governance “guarantees that data can be trusted, and that people can be made accountable for any adverse event that happens because of poor quality.”32 Therefore, data governance stakeholders are also key stakeholders for data resilience, given that data quality is a key driver of some of the dimensions of data resilience.33
Within the data governance discipline, operational metadata (e.g., operational glossaries and data dictionaries) rather than technical metadata (e.g., schema definitions) have the lowest frequency count in the literature, suggesting that interest in how data are interpreted has been lagging so far.34
Ignoring metadata is a significant operational risk, though. Since data have a context—which should be captured as metadata to mitigate sustainability risk—and are the foundation of statistical AI, it is problematic if metadata are not captured and maintained. Metadata are necessary to present a shared understanding of the interpretation of organizational data and to mitigate the continuity risk of AI staff leaving and new staff entering the organization. If it is possible that different AI models interpret the same input data differently due to the absence of appropriate metadata, what possible confidence can there be in enterprise AI outcomes? This risk compromises data resilience.
The growing, early-stage35 concept of the data fabric—a metadatacentric approach to data management (or networkcentric approach if seen through a technical architect’s lens)—views metadata and their related management tools as the heart of the organization’s heterogeneous data universe. The data fabric market is expected to double between 2021 and 2028.36 Another emerging high-level architectural approach is data mesh, which organizes around data domain expertise.37 Ignoring the value of metadata hinders the adoption of new data management paradigms in increasingly complex data milieus that are subject to continuous, dynamic change.
According to the Khatri and Brown framework, in addition to data quality and metadata, there are two other important data governance decision domains (figure 6): data access and data life cycle management.38

An adverse event (i.e., realization of risk) can arise from poor data quality, from poor metadata, or as a consequence of decisions regarding data access and data life cycle management (figure 7). These risk factors need to be controlled, and people must be held accountable for them to minimize the potential for adverse events in the data space and ensure data resilience. After all, data resilience is a form of risk management.39

Source: (a) Sutherland, I.; “Industrial Espionage From Residual Data: Risks and Countermeasures,” 6th Australian Digital Forensics Conference, 3 December 2008,
http://ro.ecu.edu.au/cgi/viewcontent.cgi?article=1052&context=adf
Ignoring the value of metadata hinders the adoption of new data management paradigms in increasingly complex data milieus that are subject to continuous, dynamic change.
Real-World Data Resilience
So which roles fulfill data resilience activities (strategic, tactical and operational)? Based on figure 1, a sample of relevant roles would include strategists (enterprise, IT and data), instructional designers, change and transformation leads, data stewards, data managers, data analysts, data engineers, data scientists, data governance leads, IT governance leads, security officers, privacy officers, risk managers, designers, developers, deployment teams, configuration teams, IT and data operations teams, cloud engineers, and even platform, application and data architects.
However, it is not only the identification of the roles—and subsequent responsibilities—that is key to operationalizing integrated data resilience; it is also necessary to understand that different economic sectors will have different approaches to data resilience. For example, little, if anything, speaks more to the importance of data resilience than recognizing that the operation of the entire global financial system depends on it. It is essential to have a robust and resilient digital data infrastructure to facilitate the seamless flow of data between global market participants and end users.40 Any disruption in financial flows can prevent an individual from buying the latest gadget, a local merchant from paying for goods for resale, an importer paying an international supplier in its currency or an organization from being able to acquire another. It can prevent the flow of capital from going to wherever in the world it is best employed. In short, without data resilience in financial markets, the only means of transferring utility between entities might be the barter system.
These issues and their impact on the development of a data resilience strategy are not necessarily relevant to all sectors. Organizations must create their own sector- and organization-specific data resilience strategies and define the relevant roles and responsibilities to suit them to ensure the execution of those strategies.
Almost independent of roles or sector, though, is that cloud and data resilience systems have increasingly been mentioned in the same context since their introduction at least 10 years ago,41 with a top selling point of the cloud being its inherent data resilience.42 The cloud is not only about enacting data resilience,43 however, it is also the engine that will increase the scope and impact of AI as an SaaS offering.44 Cloud services enable organizations to leverage AI to introduce new capabilities and to achieve quicker results from them.45 The requirements for trustworthy AI include resilience with respect to cyberattacks; a fallback plan for when things go wrong; accuracy, reliability and reproducibility; assurance of the privacy, quality and integrity of data, with appropriate data access permitted through data governance; and traceability, auditability and explainability.46 Many of these requirements are inherent in the dimensions of data resilience47 shown in figure 1.
The relationships between data resilience, AI, data governance and the cloud—the latter being increasingly instrumental to the growing functionality and capability of the former three items—are represented in figure 8. The relationships highlight similarities between the dimensions that are deemed important across each of the four disciplines.

As an example of these relationships, availability, a core aspect of data resilience is also a characteristic important not only to trustworthy AI, but also to data governance and even to cloud adoption. The question of availability is as important for cloud adoption as it is for data resilience, raising questions about the risk inherent in considering the cloud as a panacea for data resilience problems.
The relationships articulated in figure 8 imply that the roles identified are also related. For example, strategists, architects, data professionals, governance professionals and risk managers are almost compelled to work together in the integrated pursuit of the organization’s data resilience objectives. Failure to do so will almost certainly result in suboptimal data resilience outcomes due to the shortcomings associated with siloed work such as poor/nonexistent interdiscipline communication, duplicated work and amplified operational risk.
Organizations must create their own sector- and organization-specific data resilience strategies and define the relevant roles and responsibilities to suit them to ensure the execution of those strategies.
In terms of the day-to-day roles and responsibilities involved in data resilience regardless of sector, there are three important considerations to take account for:
- The cloud is not a panacea for data resilience.
- Data governance in the cloud is more complex than data governance on-premises.
- Strategic or operational drift is a major driver of the need for frequent data resilience plan reviews.
Cloud: Not a Panacea
Given the adoption of cloud services by a growing number of organizations, any cloud outages will disrupt increasingly more enterprises, thereby compromising data resilience. Most cloud services are concentrated in the three service providers shown in figure 9. There have been at least 24 cloud service outages with the top three cloud vendors over the last three years (figure 9).

Sources: (a) Iyengar, V.; S. Gupta; S. Vallaban; A. Sundarraman; C. Watt;
“Achieve Cloud Resilience Through Systematic and Chaotic Testing,”
Infosys Knowledge Institute Insights, August 2020, www.infosys.com/iki/insights/achieve-cloud-resilience.html; (b) Ellis, B.; “Multicloud Is Hard,
But Single-Cloud Failures Make it Necessary for Enterprises,” Forrester, 7
December 2021, http://www.forrester.com/blogs/multicloud-is-hard-but-single-cloud-failures-make-it-necessary-for-enterprises/
Figure 9 maps some of the major cloud outages over time. While four Amazon Web Services (AWS) outages were deemed large in 2021, AWS had more than 27 outages in the United States during 2021.48 It is not only the volume of outages that is of concern; duration and location matter, too. For example, in December 2021, there was a five-hour outage that affected the east coast of the United States, and a 2.5-hour outage impacting “… a wide range of online giants….”49 A Microsoft Cloud outage on December 15 impacted Active Directory functionality for 1.5 hours, preventing users around the world from logging on to services such as O365.50 A 3 March 2021 outage lasted six hours, impacting customers of a US data center.51 A Google Cloud outage impacted services in multiple regions for 3.5 hours, while a 14 December 2020 outage lasted one hour but impacted Gmail, Google Drive, Google Classroom and YouTube access for those not already logged in.52
The cloud vendor concentration risk means that a cloud outage at any cloud vendor has the potential to incur operational and sustainability risk for millions of client organizations simultaneously and to millions of retail customers with smart home technology. The desire to avoid this risk is the reason organizations increasingly consider multicloud rather than single-cloud environments as part of their approach to data resilience.
Cloud outages raise another risk for organizations considering cloud adoption for data resilience. For example, IBM found that its cloud outage in 2020 was caused by a third party.53 What due diligence is required of organizations dependent on cloud services for data resilience before they sign up with a cloud provider? In cybersecurity, it is the organization’s responsibility to ensure that service providers meet their security standards. In other words, the overall responsibility for cyberrisk management cannot be transferred to a vendor. Should organizations adopt this mindset when considering cloud vendors for data resilience? That is, should they expect the cloud vendor to be accountable for any disruptions that might occur rather than transferring responsibility for a disruption to a third-party service provider?
At an organizational level, leveraging cloud services to manage one or two of at least eight dimensions of data resilience—such as data security and data availability (figure 1)54—may reduce operational risk. However, at a global level, the aggregation of significant volumes of data “by a handful of cloud service providers” poses single-point-of-failure risk for systemic financial stability.55 Special care is, therefore, warranted for cloud-based data resilience strategies for global and domestic systemically important financial institutions, the types of financial institutions whose failures would pose significant risk to the stability of the global financial system.
Data Governance in the Cloud vs. On-Premises
While security has historically been a real and major inhibitor of cloud adoption,56 research finds that IaaS workloads recorded 60 percent fewer security incidents than on-premises environments in 2020.57 Of those, 41 percent of cloud security issues are related to governance and legal issues—with data governance considered one of the most important aspects of cloud governance.58 Also, the delay in discovering a cyberattack in the cloud can be up to 51 percent longer than identifying that same attack on-premises,59 highlighting another challenge of data governance in the cloud.
One of the greatest differences between on-premises data governance and cloud data governance concerns the diversity of stakeholders—many of whom are external and typically employees of the cloud provider—who would need to make up part of the data governance structure. Other issues that apply to data governance in the cloud include storage geographies, data processing, regional regulatory requirements and audit policies.60 Further, cloud providers need to demonstrate transparency and accountability to cloud clients in order to gain their trust.61
Data Resilience Plan Reviews
Most of the dimensions of data resilience are negatively impacted by unchecked drift, and data resilience as a whole is, therefore, also affected, as shown in figure 10.

Conclusion
The pandemic has shed a light on many organizations’ data shortcomings, with 93 percent of enterprises having experienced the impact of poor data management (as reflected by some of the dimensions of data resilience shown in figure 1) as a consequence.62 Supply chains have been so impacted by the pandemic that data resilience has been adopted as a risk mitigation strategy, with controls for factors such as data integrity, data storage, data use, cybersecurity and data disruption being identified as fundamental to improving supply chain data integrity.63
Most of the dimensions of data resilience are negatively impacted by unchecked drift, and data resilience as a whole is, therefore, also affected.
Data resilience is not only about being able to bounce back from, say, adverse availability and security events using cloud technology. Rather, data resilience is also about the data integrity safeguards that are fundamental to trustworthy AI and the reliance of good AI on good data governance. Caution should be exercised with respect to single cloud solutions for data resilience. Further, the cloud does not address all the dimensions of data resilience; data governance in the cloud is more complex than on-premises data governance and drift can significantly compromise the effectiveness of an organization’s entire data resilience plan.
Given the real-world dynamics between data resilience, AI, data governance and data integrity—and the direct or indirect impact of those dynamics—drift in any one dimension in any one of these disciplines can significantly impact any or all of the other disciplines. The implications need to be managed in the interest of appropriately securing enterprise data resilience. Two words come to mind in the context of managing drift in a systems context as far as it relates to data resilience: robustness and reconfigurability. Robust systems perform well in the presence of unexpected events, while reconfigurable systems cost-effectively permit new or modified capabilities in response to drift.
Resilience-based management is a higher order activity than risk-based management, given the ambiguous (vs. uncertain) nature of potential incidents.64 Sound real-world data resilience depends on system and data management designs that can operate well outside of their original design parameters, with component parts that can be rearranged to produce new capabilities in the event of adversity. Because true robust system design is often prohibitively expensive, the need for an increasingly reconfigurable environment in the interests of resilience is pressing. The value of a loosely coupled IT architecture—a paradigm already embraced in leading organizations—is evident. An organization that already practices loose coupling is in a very good position to establish the structures required to practice effective real-world data resilience.
Robust systems perform well in the presence of unexpected events, while reconfigurable systems cost-effectively permit new or modified capabilities in response to drift.
Endnotes
1 Online Etymology Dictionary, “Data,” http://www.etymonline.com/word/data
2 Online Etymology Dictionary, “Resilience,” http://www.etymonline.com/word/resilience
3 Bullinaria, J. A.; “IAI: The Roots, Goals and
Sub-Fields of AI,” University of Birmingham School
of Computer Science, United Kingdom, 2005, http://www.cs.bham.ac.uk/~jxb/IAI/w2.pdf
4 Pearce, G.; “Data Resilience Is Data Risk
Management,” ISACA® Journal, vol. 3, 2021, http://h04.v6pu.com/archives
5 Digital Innovation Center of Excellence,
“Cyber Data and Resilience,” http://dice.inl.gov/cyber-data-resilience/
6 Zimba, A.; Z. Wang; L. Simukonda; “Towards
Data Resilience: The Analytical Case of Crypto
Ransomware Data Recovery Techniques,”
International Journal of Information
Technology and Computer Science, vol. 1, 2018, www.mecs-press.org/ijitcs/ijitcs-v10-n1/IJITCS-V10-N1-5.pdf
7 Werner, L.; G. Burch; “Migrating to the Cloud: How
the COVID-19 Pandemic Has Affected the IT
Landscape,” ISACA Journal, vol. 1, 2022, http://h04.v6pu.com/archives
8 Eurostat, “Cloud Computing—Statistics on the
Use By Enterprises,” December 2021, http://ec.europa.eu/eurostat/statistics-explained/index.php?title=Cloud_computing_-_statistics_on_the_use_by_enterprises#:~:text=41%20%25%20of%20EU%20enterprises%20used,mail%20and%20storage%20of%20files.&text=Compared%20with%202020%2C%20the%20use,the%20retail%20trade%20in%202021
9 Ibid.
10 Lateef, Z.; “Types of Artificial Intelligence You Should Know,” Edureka, 29 July 2021, http://www.edureka.co/blog/types-of-artificial-intelligence/
11 Op cit Bullinaria
12 Yalçın, O. G.; “Symbolic vs. Subsymbolic
AI Paradigms for AI Explainability,” Towards
Data Science, 21 June 2021, http://towardsdatascience.com/symbolic-vs-subsymbolic-ai-paradigms-for-ai-explainability-6e3982c6948a
13 Copeland, B. J.; “Artificial Intelligence,”
Encyclopaedia Britannica, 20 July 1998, http://www.britannica.com/technology/artificial-intelligence
14 Ibid.
15 Ibid.
16 Kerns, J.; “What’s the Difference Between Weak
and Strong AI?” Machine Design, 15 February 2017, http://www.machinedesign.com/markets/robotics/article/21835139/whats-the-difference-between-weak-and-strong-ai
17 Op cit Copeland
18 Strickland, E.; “Fifteen Graphs You Need to See to
Understand AI in 2021,” IEEE Spectrum, 15 April 2021, http://spectrum.ieee.org/the-state-of-ai-in-15-graphs
19 Koerner, K.; “Privacy and Responsible AI,” The Privacy Advisor, http://iapp.org/news/a/privacy-and-responsible-ai/
20 Ibid.
21 Janssen, M.; P. Brous; E. Estevez; L. Barbosa; T.
Janowski; “Data Governance: Organizing Data for
Trustworthy Artificial Intelligence,” Government
Information Quarterly, vol. 37, iss. 3, July 2020, http://www.sciencedirect.com/science/article/abs/pii/S0740624X20302719
22 Pearce, G.; “Data Auditing: Building Trust in
Artificial Intelligence,” ISACA Journal, vol. 6, 2019,
http://h04.v6pu.com/archives
23 Hintze, A.; “Understanding the Four Types of
Artificial Intelligence,” Government Technology, 14 November 2016, http://www.govtech.com/computing/understanding-the-four-types-of-artificial-intelligence.html
24 Joshi, N.; “Seven Types of Artificial Intelligence,” Forbes, 19 June 2019, http://www.forbes.com/sites/cognitiveworld/2019/06/19/7-types-of-artificial-intelligence/?sh=2a1890d8233e
25 Zaïane, O. R.; “Rich Data: Risks, Issues,
Controversies and Hype,” 2nd Annual International
Symposium on Information Management and
Big Data, Cusco, Peru, September 2015, http://ceur-ws.org/Vol-1478/SIMBig2015_proceedings.pdf#page=21
26 CBInsights, “AI in Numbers Q2’20: Deals Drop
Amid Covid-19 Uncertainties,” 28 July 2020, http://www.cbinsights.com/research/report/ai-in-numbers-q2-2020/
27 CBInsights, “Retail AI Trends to Watch In 2021,” 7 July 2021, http://www.cbinsights.com/research/report/retail-ai-trends/
28 Op cit Strickland
29 Gutierrez, D.; “Big Data Industry Predictions for
2022,” Inside Big Data, 15 December 2021, http://insidebigdata.com/2021/12/15/big-data-industry-predictions-for-2022/
30 Alhassan, I.; D. Sammon; M. Daly; “Data
Governance Activities: An Analysis of the
Literature,” Journal of Decision Systems, 16 June 2016, http://www.tandfonline.com/doi/full/10.1080/12460125.2016.1187397
31 Ibid.
32 Koltay, T.; “Data Governance, Data Literacy
and the Management of Data Quality,” IFLA Journal, vol. 42, iss. 4, 30 November 2016, http://journals.sagepub.com/doi/full/10.1177/0340035216672238
33 Op cit Pearce, 2021
34 Op cit Alhassan
35 The Insight Partners, “Data Fabric Market Size
($2,466.12Mn by 2028) Lead by Real-Time
Analytics (10.3% CAGR) Impact of Coronavirus
Outbreak and Global Analysis and Forecast
by TheInsightPartners.com,” GlobeNewsWire, 26 October 2021, http://www.globenewswire.com/news-release/2021/10/26/2321093/0/en/Data-Fabric-Market-Size-2-466-12Mn-by-2028-Lead-by-Real-Time-Analytics-10-3-CAGR-Impact-of-Coronavirus-Outbreak-and-Global-Analysis-Forecast-by-TheInsightPartners-com.html
36 Ibid.
37 Woodie, A.; “Data Mesh vs. Data Fabric:
Understanding the Differences,” Datanami, 25 October 2021, http://www.datanami.com/2021/10/25/data-mesh-vs-data-fabric-understanding-the-differences/
38 Op cit Alhassan
39 Op cit Pearce, 2021
40 Haksar, V.; Y. Carrière-Swallow; A. Giddings; E.
Islam; K. Kao; E. Kopp; G. Quirós-Romero; “Toward
a Global Approach to Data in the Digital Age,”
International Monetary Fund, 6 October 2021, www.imf.org/en/Publications/Staff-Discussion-Notes/Issues/2021/10/06/Towards-a-Global-Approach-to-Data-in-the-Digital-Age-466264
41 Chong, R.; “Data Resiliency on the Cloud,” IBM, 30 November 2011, http://www.ibm.com/blogs/cloud-computing/2011/11/30/data-resiliency-on-the-cloud/
42 Forrester, “Multicloud Is Hard, But Single-Cloud
Failures Make It Necessary for Enterprises,” Forbes, 8 December 2021, http://www.forbes.com/sites/forrester/2021/12/08/multicloud-is-hard-but-single-cloud-failures-make-it-necessary-for-enterprises/?sh=5c2c3d5154e6
43 Knauer, G.; Resiliency Redefined: The Cloud-Scale Platform for Business Continuity, Nutanix, November 2019, http://www.nutanix.com/content/dam/nutanix-cxo/pdf/CXO_BusinessContinuity_Content_B_HR.pdf
44 Alton, L.; “Four Ways AI Is Improving Cloud
Computing,” Connected, 5 June 2019, http://community.connection.com/4-ways-ai-is-improving-cloud-computing/
45 Ng, A.; “Resilient Data Systems in the COVID-19
Era,” BDO Canada, 31 March 2020, http://www.bdo.ca/en-ca/insights/advisory/technology/resilient-data-systems-covid-19-era/
46 High-Level Expert Group on Artificial Intelligence,
Ethics Guidelines for Trustworthy AI, European
Commission, 8 April 2019, http://www.aepd.es/sites/default/files/2019-12/ai-ethics-guidelines.pdf
47 Op cit Pearce, 2021
48 Staff, “Amazon Cloud Unit Recovers From Brief
Outage Affecting Third-Party Services,” Reuters, 15 December 2021, http://www.reuters.com/markets/commodities/amazon-owned-twitch-down-many-users-2021-12-15
49 Gregg, A.; D. Harwell; “Amazon Web Services’
Third Outage in a Month Exposes a Weak Point in the Internet’s Backbone,” The Washington Post, 22 December 2021, http://www.washingtonpost.com/business/2021/12/22/amazon-web-services-experiences-another-big-outage/.
50 Hicks, M., “Azure AD Outage Analysis:
December 15, 2021,” CISCO ThousandEyes, 15 December 2021, http://www.thousandeyes.com/blog/azure-ad-outage-analysis-december-15-2021
51 Hatzor, Y., “A Look Back: The Biggest Cloud
Downtime Events of 2020,” Parametrix Insurance, 5 January 2021, http://parametrixinsurance.com/a-look-back-the-biggest-cloud-downtime-events-of-2020/
52 Ibid.
53 Tsidulko, J.; “IBM Blames Massive Cloud Outage
on Third-Party Network Provider,” CRN, 10 June 2020, http://www.crn.com/news/cloud/ibm-blames-massive-cloud-outage-on-third-party-network-provider
54 Op cit Pearce, 2021
55 Op cit Haksar et al.
56 Ramachandra, G.; M. Iftikhar; F. Aslam Khan;
“A Comprehensive Survey on Security in Cloud
Computing,” Procedia Computer Science, vol.110, 2017, http://www.sciencedirect.com/science/article/pii/S1877050917313030
57 Cameron, T.; “Why the Public Cloud Is More
Secure Than an On-Premises Data Center,” Explicity, http://eplexity.com/blog/why-the-public-cloud-is-more-secure-than-an-on-premises-data-center/
58 Al-Ruithe, M.; E. Benkhelifa; K. Hameed; “Data
Governance Taxonomy: Cloud Versus Non-Cloud,” Sustainability, vol. 10, iss. 1, 2 January 2018, http://www.mdpi.com/2071-1050/10/1/95
59 Herzog, E.; “Building Confidence With Data
Resilience,” InformationWeek, 22 April 2021, www.informationweek.com/security-and-risk-strategy/building-confidence-with-data-resilience
60 Op cit Al-Ruithe et al.
61 Ibid.
62 Experian, “Our 2021 Global Data Management
Research Highlights,” February 2021, http://www.experian.co.uk/blogs/latest-thinking/data-quality/our-2021-global-data-management-research-highlights/?utm_source=Twitter&utm_medium=Organic&utm_campaign=B2B-UK-FY22Q1-260421-DG-WP
63 Canadian Information Processing Society, “Global Standard for Procurement and Supply,” 20 May 2021, http://globalstandard.cips.org/segments/segment-3.6-data-integrity-in-supply-chains/
64 Trump, B.; M. Florin; V. Florin; I. Linkov (Eds.);
IRGC Resource Guide on Resilience (vol. 2):
Domains of Resilience for Complex Interconnected
Systems, 2018, http://irgc.org/wp-content/uploads/2018/12/Heinimann-for-IRGC-Resilience-Guide-Vol-2-2018.pdf
GUY PEARCE | CGEIT, CDPSE
Has an academic background in computer science and commerce and has served in strategic leadership, IT governance, and enterprise governance capacities, mainly in financial services. He has been active in digital transformation since 1999, focusing on the people and process integration of emerging technology into organizations to ensure effective adoption. Pearce was first exposed to artificial intelligence (AI) in 1989, and he has followed the evolution of the discipline from symbolic AI to statistical AI during the intervening decades. He was awarded the 2019 ISACA® Michael Cangemi Best Author award for contributions to IT governance, and he consults in digital transformation, data governance and IT governance.