
Transforming business frontiers have created an expanding digital universe and explosive data growth, requiring organizations to act as reservoirs and graveyards of data. With the amount of data that exists doubling every 2 years,1 the struggle to administer data magnifies, often resulting in the data endlessly staying put and data disposition undertakings becoming vague and daunting. Although data are instrumental in driving business and consumer value, it is even more critical to have visibility of the data collected and processed, understand their business purpose, and understand what data should be retained vs. disposed.
Defensible data disposition is an important step in the data minimization journey. It enables organizations to use a risk-based approach to systematically dispose of data that have reached the retention threshold set forth by the baseline data retention requirements in alignment with business, compliance and legal obligations, such as Brazil’s Lei Geral de Proteçao de Dados (LGPD), the EU General Data Protection Regulation (GDPR), France’s Commission nationale de l’informatique et des libertés (CNIL), Germany’s Bundesdatenschutzgesetz (BDSG), and the US State of California Consumer Privacy Act (CCPA).
Multiple factors drive the need for defensible data disposition; however, setting up a practical data disposition routine is often challenged by shortcomings as described in figure 1.
Figure 1—Data Disposition Challenges
|
Data-hoarding mindset |
Organizations may seek to retain data indefinitely due to competitive reasons without considerable thought to the rightful use of the data and its implications. |
|
Misconceptions of processed data |
The timely tracking and disposition of data are contingent on the visibility of processed structured and unstructured data elements, the architecture of associated systems and data flow intersections, which are often not complete. |
|
Limited governance and business integration |
Limited governance and coordination among business stakeholders to drive and execute data disposition efforts could be caused by ambiguity on the who, what, why and how of the data disposition effort. |
|
Opacity around data retention and disposal thresholds |
National and international privacy laws and regulations are divergent on data retention expectations (some have longer retention schedules than others for a selected data type, such as customer complaint). Instilling a common data disposition denominator is often a challenge. |
|
Technology limitations |
Legacy platforms that are overstrained with incremental repairs and systems with composite or high availability/ zero downtime data architectures cause difficulties and disagreements on executing data disposal. |
A Practical Approach to Starting the Data Disposition Journey
Figure 2 illustrates the methodology for data disposition. The methodology is applicable to the following scenarios:
- Organizations that intend to execute data disposition for retrospective systems and data that are in operation
- Organizations that intend to proactively set up a routine for systematically disposing data when they reach the data disposition threshold
- Organizations that respond to on-demand user requests or exercises of user rights to dispose data when there is no legitimate business need
Figure 2— Data Disposition Methodology
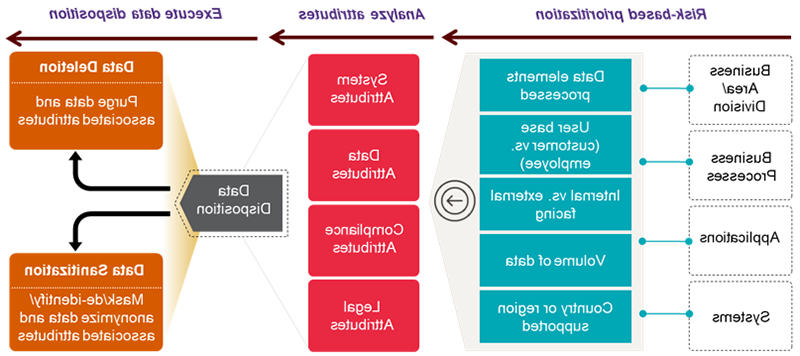
There are steps that set the minimum baseline for executing a defensible data disposition program. In addition, compliance to privacy mandates should be continually reviewed from the perspective of changes and updates to national and international privacy laws and regulations.
Step 1: Foundational Data Disposition Capabilities
A governance and operating model is fundamental for an organization to drive meaningful and timely coordination of a repeatable data disposition routine. The following steps summarize the considerations to establish foundational data disposition capabilities:
- Set up a governance and operating model and operating procedures to execute data disposition.
- Characterize data categories and data elements that are relevant to the organization and identify data retention and disposition requirements based on the organization’s applicable binding rules, business obligations and national/international laws and regulations.
Considerations
Data categories and data elements processed by business process, system and application vary, and data deletion requirements should factor in the data processed and the data subjects that are related to them, such as employees, customers and vendors.
Step 2: Risk-Based Prioritization
Operationalizing data disposition all at once will be challenging, if not unlikely. A risk-based approach to data deletion helps identify and prioritize business processes that are critical and to organize the data disposition undertaking into modules of incremental value. The following steps summarize the considerations to establish risk-based prioritization:
- Define the boundaries of business process and system for data disposition and prioritize them based on factors such as the category and type of data processed, user base (such as customer facing or internal facing), volume of data processed, and associated regions and jurisdictions supported.
- Leverage the prioritized listing to group the business process, system and application based on their compounding risk to the organization.
Considerations
Data are shared between systems; therefore, understanding the data lineage is important to discern the risk-based priorities holistically. A system or application may pose less risk when reviewed in isolation, but it may render a higher risk posture when the upstream and downstream interfaces are taken into account.
Data are shared between systems; therefore, understanding the data lineage is important to discern the risk-based priorities holistically.
Step 3: Analyze System, Data and Compliance Attributes
A typical digital business landscape is characterized as a complex web of relationships with a host of systems, devices and data interactions cutting across several business processes. Accurate and credible insights into the upstream and downstream inter-relationships of business process, system and data are vital to plan and manage data disposition rationally. The following steps summarize the considerations to evaluate the attributes that define the scope and boundary conditions of data disposition:
- The system architecture and the interconnections within it are often nuanced, and at each intersection the data might be shared from one system to other system in various forms. Analyze system attributes, including the data source and destination, system type (i.e., enterprise data warehouse, big data, soon to sunset, legacy systems), system operations (i.e., real time, time triggered, online) and system ownership (i.e., hosted, cloud, vendor managed).
- Analyze data attributes, including how data are collected, processed and stored. It is also important to understand the data model, such as whether it has relational or nonrelational data structures, and analyze based on the category of data, data subjects (i.e., employee, vendors, customers or a combination of users) and earliest date of a record stored in a system (including production, nonproduction and offline backups).
- The level of legal and compliance considerations sets the baseline retention goals/expectations and resets data disposition baselines whenever there is litigation or legal hold. Analyze for target retention schedule, data categories that are subject to litigation and qualifiers for data disposition, which set the conditions of when the data should be purged (i.e., completion of transaction, record creation date, end date of user relationship).
Considerations
Some systems support multiple data categories and countries and might be subject to varying retention requirements. Determining the target retention period or purge qualifier should be based on reasonable risk-based methods.
Understanding the data lineage is important to discern the systems of record (source of data or primary intake point of data) and systems of reference (downstream systems that fetch data from systems of record). Data disposed only on the system of reference level (downstream system) will not render any value as the system of record will still hold the data and update the downstream system during the next refresh cycle.
Step 4: Dispose Data
Defensible data disposition can be accomplished through various methods and are broadly grouped into the following types:
- Data deletion—The method of purging data and associated reference attributes that will be completely erased and not available for future use
- Data pseudonymization—The method of substituting identifiable data with a randomly generated number or token. This method offers the ability to re-identify data with additional information (such as a key). This method should be considered when storing or using personal data that may later need to be accessed in full for the functioning of required business use cases.
- Data anonymization—The method for pseudonymization and anonymization is often similar—the main difference being that pseudonymization is performed with the intention to retain the ability for re-identifying individuals within the data sets. Anonymization is irreversible; the original values are disposed of properly. This should be used for personal values where there is no business need to retain the data in a fully identifiable format.
- Data masking—Character masking is the change of the characters of data values. Masking is typically partial and applied only to some characters in the attribute. This is to be used when the data value is a string of characters and hiding part of it is enough to provide the extent of anonymity required.
- Data tokenization—The method of replacing sensitive data with unique identification symbols or algorithmically generated number that retain all the essential information about the data without compromising their security
Considerations
The business need and legal basis should define the type of data disposition that is optimal to the business.
Conclusion
Traditional practices often do not consider the data privacy interests of end users, such as data minimization and timely data disposition. The new generation of consumer behaviors and expectations demand privacy-friendly business operations. The legal and regulatory and consumer demands aggregate as strong forces and compelling drivers for defensible data disposition. Organizations must operate in ways that allow for the highest possible measure of consumer trust and rethink the way data disposition is managed.
Endnotes
1 EMC2, IDC, The Digital Universe of Opportunities: Rich Data and the Increasing Value of the Internet of Things, April 2014
Sudhakar Sathiyamurthy, CISA, CRISC, CGEIT, CIPP, ITIL (Expert)
Is an experienced leader with wide-ranging global experience in helping organizations and risk leaders plan and execute on their security and privacy goals and strategies. Sathiyamurthy advises clients on standing up and scaling user-centric security and privacy risk solutions and help clients design and engineer technologies that help achieve a risk-intelligent posture. Sathiyamurthy can be contacted at sudsathiyam@gmail.com.